由于拉钩网页面做了一些更新,之前的程序无法正常工作,本篇文章做一次更新。只更新一些程序和一些程序的实现方法。由于没有仔细修改,可能前后语言不通顺,大家谅解。
大家好,几天没有更新了。相信大家经过前两篇的练手爬虫,大家已经知道如何抓取一个简单网站。
这篇文章我们来抓取 拉钩网 的招聘信息。全部抓取大概十几万条全国招聘信息,并且保存数据库。
准备
安装Mongodb数据库
其实不是一定要使用MongoDB,大家完全可以使用MySQL或者Redis,全看大家喜好。这篇文章我们的例子是Mongodb,所以大家需要 下载 它。
在Windows中。由于MongoDB默认的数据目录为C:\data\db,建议大家直接在安装的时候更改默认路径为C:\MongoDB.
然后创建如下目录文件:
C:\data\log\mongod.log //用于存储数据库的日志
C:\data\db //用于存储数据库数据
然后在C:\MongoDB文件夹下(安装 Mongodb 路径)创建配置文件mongod.cfg。并且在配置文件里写入以下配置:
systemLog:
destination: file
path: C:\data\log\mongod.log
storage:
dbPath: C:\data\db
大家记住要打开文件后缀名,不然我们可能创建了一个mongod.cfg.txt文件。
最后我们需要打开管理员权限的 CMD 窗口,执行如下命令,安装数据库成服务:
"C:\mongodb\bin\mongod.exe" --config "C:\mongodb\mongod.cfg" --install
设置为服务后,需要在管理员权限打开的windows cmd窗口用服务的方式启动或停止MongoDB。
net start mongodb //启动mongodb服务
net stop mongodb //关闭mongodb服务
好了,安装好Mongodb数据库后,我们需要安装PyMongo,它是MongoDB的Python接口开发包。
pip install pymongo
开始
准备完成后,我们就开始浏览拉勾网。我们可以发现拉勾网所有的招聘职位都在左侧分类里。如图:
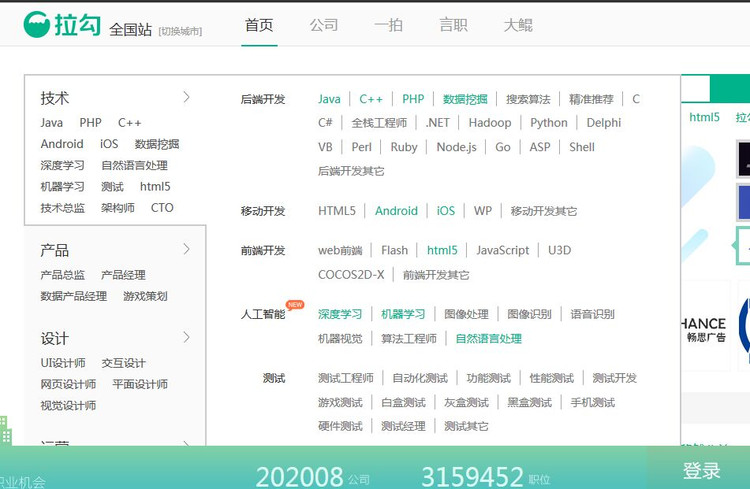
我们先获取首页HTML文件:
import requests
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
url = 'https://www.lagou.com/'
# 获取页面源码函数
def get_page_resp(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
try:
resp = requests.get(url, headers=headers)
if resp.status_code == 200:
return resp.text
return None
except RequestException:
return None
soup = BeautifulSoup(get_page_resp(url), 'lxml')
然后我们打开开发者工具,找到招聘职业的位置。
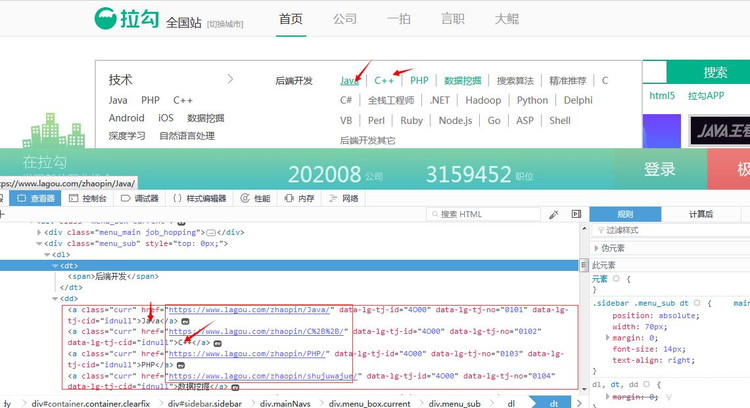
大家还记得BeautifulSoup的CSS选择器吧,我们直接使用.select()方法获取标签信息。
all_positions = soup.select('div.menu_sub.dn > dl > dd > a')
print(all_positions)
print(len(all_positions))
输出结果:
[<a class="curr" href="https://www.lagou.com/zhaopin/Java/" data-lg-tj-cid="idnull" data-lg-tj-id="4O00" data-lg-tj-no="0101">Java</a>, <a class="curr" href="https://www.lagou.com/zhaopin/C%2B%2B/" data-lg-tj-cid="idnull" data-lg-tj-id="4O00" data-lg-tj-no="0102">C++</a>, # ... 省略部分 <a class="" href="https://www.lagou.com/zhaopin/fengxiankongzhizongjian/" data-lg-tj-cid="idnull" data-lg-tj-id="4U00" data-lg-tj-no="0404">风控总监</a>, <a class="" href="https://www.lagou.com/zhaopin/zongcaifuzongcai/" data-lg-tj-cid="idnull" data-lg-tj-id="4U00" data-lg-tj-no="0405">副总裁</a>]
260
获取到所有职位标签的a标签后,我们只需要提取标签的href属性和标签内内容,就可以获得到职位的招聘链接和招聘职位的名称了。我们准备信息生成一个字典。方便我们后续程序的调用。
# 解析首页获得所有职位信息的函数
def parse_index():
url = 'https://www.lagou.com/'
soup = BeautifulSoup(get_html(url), 'lxml')
all_positions = soup.select('div.menu_sub.dn > dl > dd > a')
joburls = [i['href'] for i in all_positions]
jobnames = [i.get_text() for i in all_positions]
for joburl, jobname in zip(joburls, jobnames):
data = {
'url' : joburl,
'name' : jobname
}
# 这里使用yield语法糖,不熟悉的同学自己查看资料哦
yield data
这里我们用zip函数,同时迭代两个list。生成一个键值对。
接下来我们可以随意点击一个职位分类,分析招聘页面的信息。
分页
我们首先来分析下网站页数信息。经过我的观察,每个职位的招聘信息最多不超过 30 页。也就是说,我们只要从第 1 页循环到第 30 页,就可以得到所有招聘信息了。但是也可以看到有的职位招聘信息,页数并不到 30 页。以下图为例:
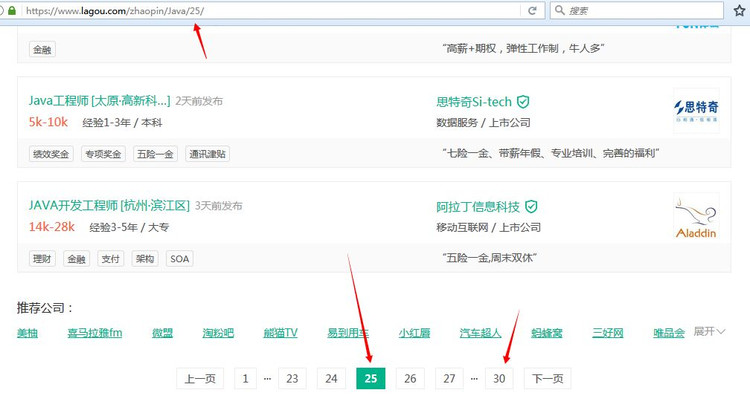
如果我们访问页面:https://www.lagou.com/zhaopin/Java/31/
也就是第 31 页。我们会得到 404 页面。所以我们需要在访问到404页面时进行过滤。
if resp.status_code == 404:
pass
这样我们就可以放心的 30 页循环获得每一页招聘信息了。
我们的每一页url使用format拼接出来:
for page in (1, 31):
link = '{}{}/'.format(url, str(page))
获取信息
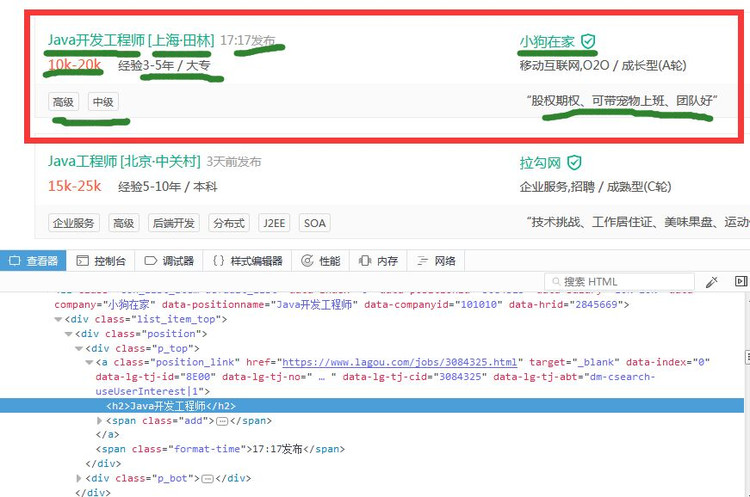
我们可以看到上面划线的信息。这就是我们要抓取的信息了。
当然。抓取的方法千篇一律,我们可以使用find()或find_all()
选择器,当然也可以使用 CSS选择器。但是 CSS选择器相对于前两者代码量稍微少一些。这里大家自己动手抓取,我们直接上代码供大家借鉴。
# 职位信息
positions = soup.select('ul > li > div.list_item_top > div.position > div.p_top > a > h3')
# 工作地址
adds = soup.select('ul > li > div.list_item_top > div.position > div.p_top > a > span > em')
# 发布时间
publishs = soup.select('ul > li > div.list_item_top > div.position > div.p_top > span')
# 薪资信息
moneys = soup.select('ul > li > div.list_item_top > div.position > div.p_bot > div > span')
# 工作需求
needs = soup.select('ul > li > div.list_item_top > div.position > div.p_bot > div')
# 发布公司
companys = soup.select('ul > li > div.list_item_top > div.company > div.company_name > a')
tags = []
# 由于我发现有的招聘信息没有标签信息,if判断防止没有标签报错
if soup.find('div', class_='li_b_l'):
# 招聘信息标签
tags = soup.select('ul > li > div.list_item_bot > div.li_b_l')
# 公司福利
fulis = soup.select('ul > li > div.list_item_bot > div.li_b_r')
获取到全部信息后,我们同样的把他们组成键值对字典。
for position,add,publish,money,need,company,tag,fuli in \
zip(positions,adds,publishs,moneys,needs,companys,tags,fulis):
data = {
'position' : position.get_text(),
'add' : add.get_text(),
'publish' : publish.get_text(),
'money' : money.get_text(),
'need' : need.get_text().split('\n')[2],
'company' : company.get_text(),
'tag' : tag.get_text().replace('\n','-'),
'fuli' : fuli.get_text()
}
组成字典的目的是方便我们将全部信息保存到数据库。
保存数据库
保存数据库前我们需要配置数据库信息:
import pymongo
client = pymongo.MongoClient('localhost', 27017)
lagou = client['lagou']
url_list = lagou['url_list']
这里我们导入了pymongo库,并且与MongoDB建立连接,这里是默认连接本地的MongoDB数据。创建并选择一个数据库lagou,并在这个数据库中,创建一个table,即url_list。然后,我们进行数据的保存:
if url_list.insert_one(data):
print('保存数据库成功', data)
如果保存成功,打印出成功信息。
多进程抓取
十万多条数据是不是抓取的有点慢,有办法,我们使用多进程同时抓取。由于Python的历史遗留问题,多线程在Python中始终是个美丽的梦。
from multiprocessing import Pool
def main(datas):
url = data['url']
print(url)
mongo_table = data['name']
# 因为有的职位是以'.'开头的,比如.Net,数据库表名不能以.开头
if mongo_table[0] == '.':
mongo_table = mongo_table[1:]
# 我们把之前抓取职位所有招聘信息的程序整理为parse_link()函数
# 这个函数接收职位url,页码,和数据库表名为参数
parse_link(url, mongo_table)
我们把之前提取职位招聘信息的代码,写成一个函数,方便我们调用。这里的parse_link()就是这个函数,他就收职位的 url 和所有页数为参数。我们get_alllink_data()函数里面使用for循环 30 页的数据。然后这个作为主函数传给多进程内部调用。
if __name__ == '__main__':
pool = Pool(processes=6)
datas = (data for data in parse_index())
pool.map(main, datas)
pool.close()
pool.join()
这里是一个pool进程池,我们调用进程池的map方法.
map(func, iterable[,chunksize=None])
多进程Pool类中的map方法,与Python内置的map函数用法行为基本一致。它会使进程阻塞,直到返回结果。需要注意,虽然第二个参数是一个迭代器,但在实际使用中,必须在整个队列都就绪后,程序才会运行子进程。join()
方法等待子进程结束后再继续往下运行,通常用于进程间的同步.
针对反爬
如果大家就这样整理完代码,直接就开始抓取的话。相信在抓取的不久后就会出现程序中止不走了。我刚刚第一次中止后,我以为是网站限制了我的 ip。于是我做了如下改动。
import random
import time
user_agent_list = [
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
' Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.2)'
]
user_agent = random.choice(user_agent_list)
headers = {
'User-Agent':user_agent,
'Connection':'keep-alive'
}
proxy_list = [
'http://140.224.76.21:808',
'http://60.178.14.90:8081',
'http://121.232.146.13:9000',
]
proxy_ip = random.choice(proxy_list)
proxies = {
'http': proxy_ip,
'https': proxy_ip,
}
resp = requests.get(url, headers=headers, proxies=proxies)
time.sleep(1)
这里我是直接在在网上找了一些免费的ip,还自己找了几个浏览器的user-agent。利用Python内置的random库,开始随机选择列表里的user-agent和ip。并且将参数传入requests内继续抓取。为了防止请求频率过快,我们设置每次请求结束停留一秒。然后我以为问题这么结束了。就开始继续抓取,但是在之前中断的位置突然有中断了。
于是,我在代码抓取信息位置添加了一句打印url的代码。我得到了中断爬取的url,然后我手动多点进去,发现了这个网页。当然出现这个情况并不是更换ip不可以,而是我们的ip太少了,一个ip可能仍然出现多次抓取的情况,后续我将会和大家一起写一个自己的ip代理池。
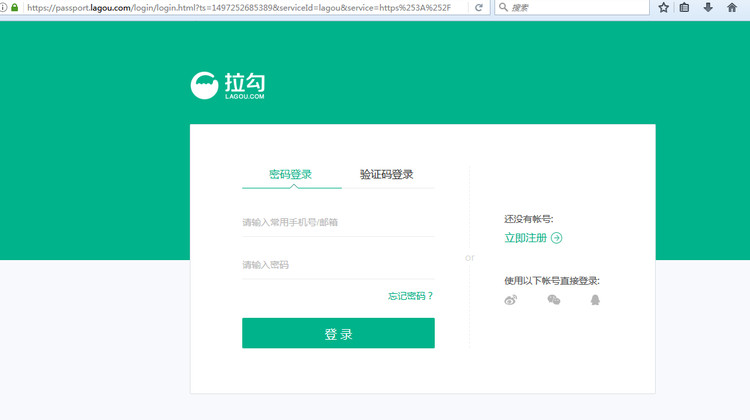
模拟登录
没错这是一个登录界面,不知道是不是这里的浏览器头,或者ip请求过多。如果继续增多ip和user_agent就不会出现这种情况。
但是如何面对这种需要登录才能持续爬取的网站呢,很简单,我们只要打开浏览器的开发者工具。登录自己的账号,在Network标签找一个请求,查看你的请求头部信息,找到自己的cookies。这个cookies就是你的登录信息了,我们需要将他和你的user-agent一样,添加到请求头就可以了。如果大家不明白这个cookies是什么,没关系,后面会有专门的讲解。
headers = {
'Cookie':'user_trace_token=20170603115043-d0c257a054ee44f99177a3540d44dda1; LGUID=20170603115044-d1e2b4d1-480f-11e7-96cf-525400f775ce; JSESSIONID=ABAAABAAAGHAABHAA8050BE2E1D33E6C2A80E370FE9167B; _gat=1; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; index_location_city=%E5%85%A8%E5%9B%BD; login=false; unick=""; _putrc=""; _ga=GA1.2.922290439.1496461627; X_HTTP_TOKEN=3876430f68ebc0ae0b8fac6c9f163d45; _ga=GA1.3.922290439.1496461627; LGSID=20170720174323-df1d6e50-6d2f-11e7-ac93-5254005c3644; LGRID=20170720174450-12fc5214-6d30-11e7-b32f-525400f775ce; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1500541369; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1500543655',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
}
好了我们继续抓取,发现这次程序并没有中止。但是由于博主网速过慢,抓取太慢了,还没有全部抓取下来,不知道后面会不会出现问题。
这次更新,我是完全抓取玩全站才过来的,没错我已经抓取了全部的信息。用时1412 .9008133411407 秒。
好了,说了这么多,基本也都说完了。
项目地址
对整理代码有疑惑的伙伴可以点击 这里。
最后
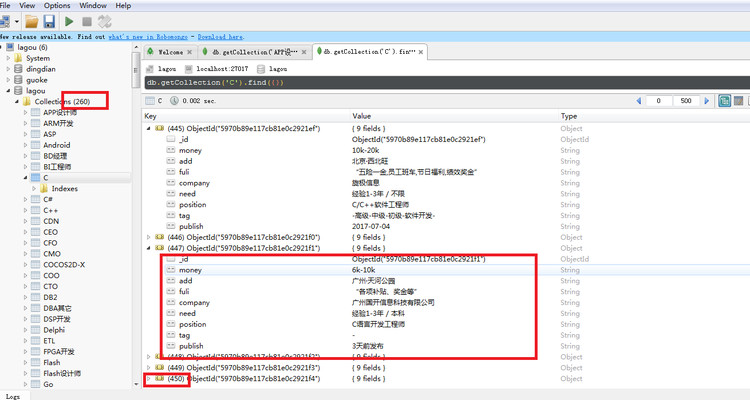
这是我已经抓取的一部分。这里如果大家希望看到Mongodb数据库里的保存内容。
我们需要安装一个Mongodb可视化应用 robomango。
安装没什么要说的,大家链接到我们的lagou数据库,就可以看到里面的数据了。
如果博主后面把全部数据抓下来后,可以和大家一起进行数据分析,分析Python招聘的一些信息啊什么的。大家加油。
谢谢阅读