前两篇文章我们了解了 Scrapy 的理论知识,那么我们不能做纸上谈兵的赵括。实践才是检验真理的唯一标准。本篇文章我们来抓取网易云音乐的所有音乐及音乐的热评。
分析站点
我们打开浏览器,访问网易云音乐的网页端。如果我们想要抓取到所有的音乐,就得有一个切入口,能够获得到所有的音乐数据。
那么通过观察页面的导航,我们只能通过获取全部的歌手。但是由于歌手详情页并没有全部音乐这个链接,我们只能获取全部的专辑。在通过全部的专辑获得全部的音乐。
爬虫流程
以歌手页为索引页,抓取所有的歌手; 通过所有的歌手抓取全部专辑; 通过全部专辑抓取所有的音乐; 分析所有音乐的Ajax,获得所有热评; 将音乐名,歌手,专辑,热评,热评作者,热评赞数保存数据库。
开始
创建项目
scrapy startproject 163music
创建爬虫文件(可以通过命令行创建):
# spiders/spider.py
from scrapy import Spider
class MusicSpider(Spider):
name = "music"
allowed_domains = ["163.com"]
base_url = 'https://music.163.com'
确定数据名称
我们先将要保存下来得到数据写到 item 文件中,虽然这一步不是必须先写,但是我们按照流程来不会错。
#items.py
import scrapy
class MusicItem(scrapy.Item):
# define the fields for your item here like:
# 我们保存歌曲的id
id = scrapy.Field()
artist = scrapy.Field()
album = scrapy.Field()
music = scrapy.Field()
comments = scrapy.Field()
分析索引页
我们的索引页为歌手页,地址:https://music.163.com/#/discover/artist/cat?id=1001&initial=65
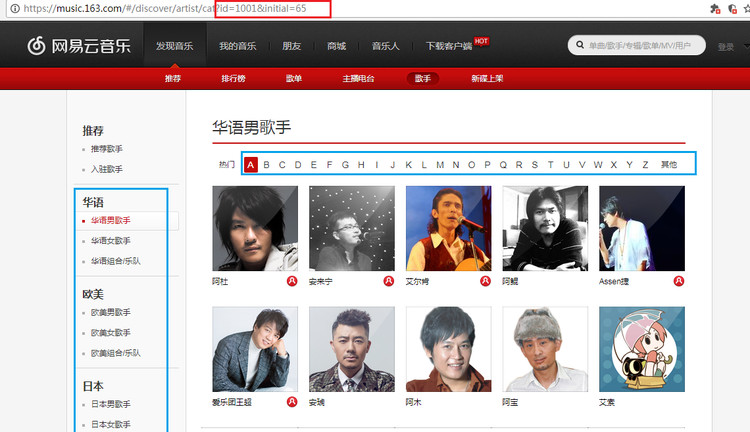
通过图片结合我们对索引页的观察,我们可以看到左侧比如华语男歌手,欧美男歌手是分类,而歌手下的ABCDE也是一个按姓名的分类。
通过观察链接可以发现,id就是左侧分类的值,initial是 ABCDE 链接的值。
我们可以发现 ABCDE 每一个链接是从 65 开始,一直到 90,再加上’其他’链接为 0。这样的规则我们是可以用代码很简单实现的。而左侧的歌手分类的数字相对是不好用代码实现他的规则的。索性他的数目不多,我们一个一个写出来保存集合就可以了。我们将这两个参数写到爬虫类中。
class MusicSpider(Spider):
name = "music"
allowed_domains = ["163.com"]
base_url = 'https://music.163.com'
ids = ['1001','1002','1003','2001','2002','2003','6001','6002','6003','7001','7002','7003','4001','4002','4003']
起始url
很显然歌手页有不同的分类,所有起始页不可能是单独的一个url,所以我们要重写start_requests。也就是构建所有的歌手分类页。
def start_requests(self):
for id in self.ids:
for initial in self.initials:
url = '{url}/discover/artist/cat?id={id}&initial={initial}'.format(url=self.base_url,id=id,initial=initial)
yield Request(url, callback=self.parse_index)
这一步实现起来逻辑还是很清晰的,循环每一个id,在循环每一个initial,将他们通过.format方法组成url。然后使用yield语法糖,将url回调给索引页解析函数。相信大家在前两篇理论的梳理下,对于这步操作没有什么问题。
那么我们在parse_index()函数中打印一下Response:
def parse_index(self, response):
print(response.text)
控制台运行爬虫:scrapy crawl music
由于scrapy不支持lde运行,所以如果我们非要想在比如pycharm中运行的话,我们需要编写一个运行程序:
# 163music/entrypoint.py
# 注意这个文件在项目的根目录,也就是scrapy.cfg文件所在
# 这里的music就是爬虫的名字
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'music'])
现在我们在pycharm做运行这个文件就相当于运行爬虫了。
运行成功,但是我们好像并没有获得到我们想要的数据。这是怎么回事呢?
大家如果回忆使用Requests库请求的时候,我们在请求中有时候会添加一些请求头,那么scrapy中我们要在哪里添加呢。
答案很简单,就是在settings.py文件中。
添加请求头设置
我们需要在settings文件中先取消掉DEFAULT_REQUEST_HEADERS的注释,因为scrapy默认我们不需要请求头。我们在里面添加网易云的头部请求,就是我们开发者工具里的数据:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Cookie':'_ntes_nuid=5e2135ea19041c08d61bddbb9009de63; _ntes_nnid=a387121ca9ed891dca82492f6c088c57,1483420952257; __utma=187553192.690483437.1489583101.1489583101.1489583101.1; __utmz=187553192.1489583101.1.1.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); __oc_uuid=ff821060-097f-11e7-8c2a-73421a9a1bc4; mail_psc_fingerprint=032ad52396a72877e07f21386dee35a2; NTES_CMT_USER_INFO=106964635%7C%E6%9C%89%E6%80%81%E5%BA%A6%E7%BD%91%E5%8F%8B06o2qr%7Chttps%3A%2F%2Fsimg.ws.126.net%2Fe%2Fimg5.cache.netease.com%2Ftie%2Fimages%2Fyun%2Fphoto_default_62.png.39x39.100.jpg%7Cfalse%7CbTE1MTUyMzQ3Mjc3QDE2My5jb20%3D; usertrack=c+5+hlkgTIMgjwa+EDUGAg==; _ga=GA1.2.690483437.1489583101; Province=025; City=05278; NTES_PASSPORT=aXWcpL4bYTLQnXY4eO888VlwXt.v922HPG1pBkj.vkeDwsISwc4gjpib7gtylUsoCy.yIGuJPZg7Uq2lTWqIo3A5ddE7eIf5DP_mjdHrg7ky2KFIZHP60ge8g; P_INFO=m15152347277@163.com|1500267468|1|blog|11&10|jis&1499527300&mail163#jis&320800#10#0#0|151277&1|study&blog&photo|15152347277@163.com; UM_distinctid=15d4ee58fc9483-032aae6568b355-333f5902-100200-15d4ee58fca912; NTES_SESS=35juNvuVAClEtPfwjy5rP5GVXVpRFMmwg2ItfudhfLmyGTk4G2l_fIFHi_xsOJTWQrUJvW3JwsMFyepEs0SR6z1_QnKjbQFaesBY9ABy0TVFP_KIiXNgb89wCGe.3_hmKR90f2ybdvNPWqPX8_YesVlIQrWdw5Nfg6KF0EcoVXO3DgV09cJHAeiE_; S_INFO=1500623480|1|0&80##|m15152347277; ANTICSRF=dd45f2a4489d303de869d820a0dadf05; playerid=64643457; JSESSIONID-WYYY=oR0Q0Ce%2Bhldid%2FFtfsiobsg%5Cecyra1qnHBuFFPNBUW%2BbZ3%5C2uq5%2Fqz4VrhRll0%5CaVCfY%2Fg0%2BC47vS%5Cv6rsyuD76tlqWN%2BUryVxph9fZeCmVIDtu5so7vdcdp%2B92hI3A0R5Zm%2Besa5l3ND%5Cz59WOYTY%2FCUjG%2B8gFSGVyzTpMquPQIxyIM%3A1500647790286; _iuqxldmzr_=32; MUSIC_U=f5333454d16d0f0ca5e59b3a82afaabcb107f5e73a4504bae87278f38158d65dbef309e3badc0bfac257abd5a88c5d62dc7e2cf554b1b3fc233a987fb3c42671e386323209b86ec1bf122d59fa1ed6a2; __remember_me=true; __csrf=5cd5b19efc6ea479e298487216162acf; __utma=94650624.776578804.1489210725.1500604214.1500644866.50; __utmb=94650624.28.10.1500644866; __utmc=94650624; __utmz=94650624.1499960824.48.42.utmcsr=yukunweb.com|utmccn=(referral)|utmcmd=referral|utmcct=/412.html',
'DNT': '1',
'Host': 'music.163.com',
'Pragma': 'no-cache',
'Referer': 'http://music.163.com/',
'Upgrade-Insecure-Requests': '1',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
}
注意,网易云音乐的歌曲提取是要我们登录才可以获得数据的,我们直接加上登录后的cookies就可以了。
现在运行爬虫,如果运行成功,那么大家应该就能看到打印出来的数据了。这说明我们的程序是正确的。
编写起始页解析函数
这一步就要使用我们的选择器提取信息了,我们打开开发者工具,我们需要的就是歌手a标签中的href信息。对于还不会使用xpath和css选择器的可以使用Chrome开发者工具,右击该标签,如下图的操作:
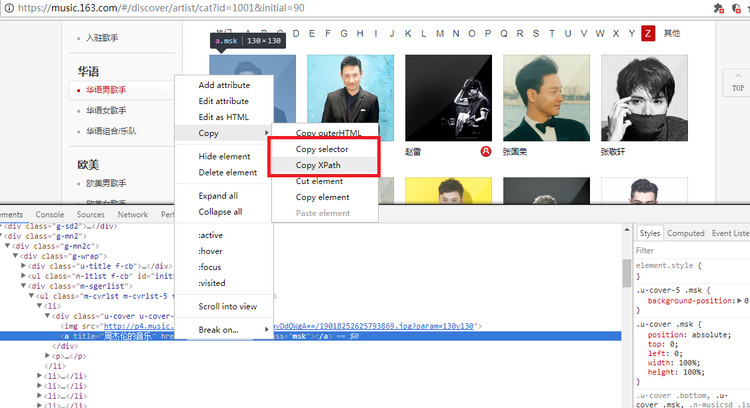
直接上解析起始页代码:
# 获得所有歌手的url
def parse_index(self, response):
artists = response.xpath('//*[@id="m-artist-box"]/li/div/a/@href').extract()
for artist in artists:
artist_url = self.base_url + '/artist' + '/album?' + artist[8:]
yield Request(artist_url, callback=self.parse_artist)
歌手专辑详情页url实例如:https://music.163.com/#/artist/album?id=6452
我们解析得到href值后,在将他组合成完整的歌手专辑详情页url。然后回调给下一个解析函数。
提取所有专辑url
这一步和上一步一样,由于这一步也没什么难点,不过多赘述。上代码:
# 获得所有歌手专辑的url
def parse_artist(self, response):
albums = response.xpath('//*[@id="m-song-module"]/li/div/a[@class="msk"]/@href').extract()
for album in albums:
album_url = self.base_url + album
yield Request(album_url, callback=self.parse_album)
提取所有歌曲
这一步就有一点不同了,因为如果我们提取了音乐url,那么我们需要的音乐id就在url中。如果我们直接将URL回调给解析音乐页的函数后,我们在后面是获取不到这个id的。大家可以自己观察页面,确定这一步。
所以我们不仅要把url回调给下一个解析函数,还要把音乐id传给下一个函数。那么大家应该会有疑问,为什么不把id直接保存到item呢。
这是因为我们需要的数据结构会是这样:
{'id':123456,'music':'晴天','artist':'周杰伦','album':'叶美惠','comments':[{'comment_author':'小明','comment_content':'我爱你','comment_like':'123456'},{...},{}...]}
如果我们现在保存了音乐id,那么后面的信息能否对应我们也不确定。那么怎样才能将数据传给下一个函数呢?
scrapy给我提供了meta参数用来保存我们的数据传给函数,我们来看代码:
# 获得所有专辑音乐的url
def parse_album(self, response):
musics = response.xpath('//ul[@class="f-hide"]/li/a/@href').extract()
for music in musics:
music_id = music[9:]
music_url = self.base_url + music
yield Request(music_url, meta={'id': music_id}, callback=self.parse_music)
像这样我们把组合的URL传给解析函数,也将音乐id传给下一个函数。
提取音乐信息,分析评论Ajax
对于提取页面的音乐信息,使用选择器提取就可以了,难的是评论区并不在我们获取的源码中。如果大家有疑惑,可以打印一些音乐详情页的源码。那么评论的信息究竟在哪呢,这是相信大家心里都开始怀疑这是不是Ajax加载的呢。
为了验证这个疑惑,我们点击评论区的翻页,可以看到到了第二页浏览器的url并没有变化。这个时候基本上可以知道这是ajax加载的页面了。
我们之前有一篇说过Ajax请求的处理方法,我们这里不多余赘述。打开Chrome开发者工具,点开Network标签的XHR刷新页面,这时候会有几个请求出来。我们一个一个点开看他们的响应内容,发现R_SO_4_186016?csrf_token=请求中包含了评论的信息。数一下热评数在对比页面中的热评信息,完全一致。我们看下面的图片:
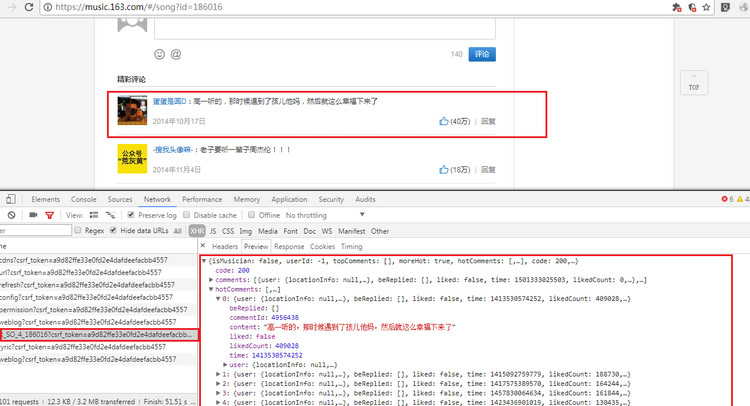
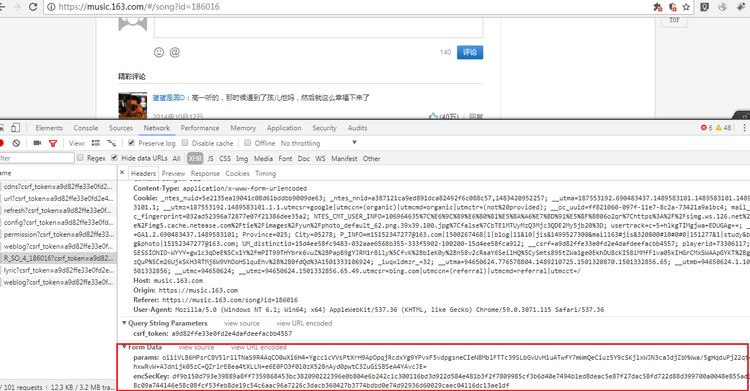
通过上面一张图片,红框里框出的Form Data数据,没错,这是一个Post请求信息。接着我们就要将他们构造成字典通过post请求。我们在看图中的referer的url,没错url后面的id就是歌曲的id。上一个函数我们将歌曲id也传过来是不是很方便这一步的处理呢。
我们需要在之前的请求头中加入每个音乐请求的referer参数。
DEFAULT_REQUEST_HEADERS['Referer'] = self.base_url + '/playlist?id=' + str(music_id)
将Form Data构造字典大家都没问题,构造Ajax请求url就是R_SO_4_后面接上音乐的id。也没问题,那么在scrapy中怎么使用Post请求呢。
答案就是scrapy的FormRequest方法,我们需要导入他,然后用法和Request一样,我们还需要将这个函数提取的所有音乐信息传给下一个提取热评的函数,然后将所有数据一起传给item。
代码如下:
# 获得音乐信息
def parse_music(self, response):
music_id = response.meta['id']
music = response.xpath('//div[@class="tit"]/em[@class="f-ff2"]/text()').extract_first()
artist = response.xpath('//div[@class="cnt"]/p[1]/span/a/text()').extract_first()
album = response.xpath('//div[@class="cnt"]/p[2]/a/text()').extract_first()
data = {
'csrf_token': '',
'params': 'Ak2s0LoP1GRJYqE3XxJUZVYK9uPEXSTttmAS+8uVLnYRoUt/Xgqdrt/13nr6OYhi75QSTlQ9FcZaWElIwE+oz9qXAu87t2DHj6Auu+2yBJDr+arG+irBbjIvKJGfjgBac+kSm2ePwf4rfuHSKVgQu1cYMdqFVnB+ojBsWopHcexbvLylDIMPulPljAWK6MR8',
'encSecKey': '8c85d1b6f53bfebaf5258d171f3526c06980cbcaf490d759eac82145ee27198297c152dd95e7ea0f08cfb7281588cdab305946e01b9d84f0b49700f9c2eb6eeced8624b16ce378bccd24341b1b5ad3d84ebd707dbbd18a4f01c2a007cd47de32f28ca395c9715afa134ed9ee321caa7f28ec82b94307d75144f6b5b134a9ce1a'
}
DEFAULT_REQUEST_HEADERS['Referer'] = self.base_url + '/playlist?id=' + str(music_id)
music_comment = 'http://music.163.com/weapi/v1/resource/comments/R_SO_4_' + str(music_id)
yield FormRequest(music_comment, meta={'id':music_id,'music':music,'artist':artist,'album':album}, \
callback=self.parse_comment, formdata=data)
提取热评信息传给item
这是爬虫部分的最后一步了,这一步从Ajax请求的json数据了提取信息,相信大家都会,就不去多说。我们提取到所有的数据后,就是传给item了。
item的操作和字典是一样的,我们就像保存字典数据一样保存他们就可以了。但是那么多数据写字典那样一步一步的是不是很蠢呢。那有没有方便一点的方法了。这个时候内置的eval方法派上用场,这里不做方法的讲解,用起来很简单,他会动态的获取我们字典的每一个键,然后帮我们保存。我们看代码:
# 获得所有音乐的热评数据
import json
def parse_comment(self, response):
id = response.meta['id']
music = response.meta['music']
artist = response.meta['artist']
album = response.meta['album']
result = json.loads(response.text)
comments = []
if 'hotComments' in result.keys():
for comment in result.get('hotComments'):
hotcomment_author = comment['user']['nickname']
hotcomment = comment['content']
hotcomment_like = comment['likedCount']
# 这里我们将评论的作者头像也保存,如果大家喜欢这个项目,我后面可以做个web端的展现
hotcomment_avatar = comment['user']['avatarUrl']
data = {
'nickname': hotcomment_author,
'content': hotcomment,
'likedcount': hotcomment_like,
'avatarurl': hotcomment_avatar
}
comments.append(data)
item = MusicItem()
# 由于eval方法不稳定,具体的可以自己搜索,我们过滤一下错误
for field in item.fields:
try:
item[field] = eval(field)
except:
print('Field is not defined', field)
yield item
最后我们将数据传给Item。
Pipeline中处理数据
在Pipeline中处理数据,其实我们这里没什么好对数据做什么改动的,这里我们要对数据做数据库的保存。
我们需要创建一个mongodb类。然后在settings中将ITEM_PIPELINES的键改为我们创建的mongdb类,由于我们不需要对数据进行改动,所以直接覆盖就好了。为了方便管理和整体架构的清晰,我们也需要在settings中设置我们的数据库信息。具体代码如下:
ITEM_PIPELINES = {
'music163.pipelines.MongoPipeline': 300,
}
# 添加数据库信息
MONGO_URI = 'localhost'
MONGO_DB = 'music163'
接下来就是写我们的Mongodb类了。首先我们需要给这个类传入两个参数,也就是我们前面在settings文件定义的数据库uri和数据库名,我们对它们进行一个赋值:
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
接下来我们定义一个from_crawler类方法,这个方法就相当于将这个类的两个参数通过crawler对象从 settings 中拿到这两个参数(数据库uri和名称)。
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
这里的@classmethod装饰器是python中比较常用的一个方法,具体操作大家可以参阅相关资料了解他。
后面的open_spider()和close_spider()方法其实是重定义的一个类方法,意思就是我们在启动爬虫的开始,调用open_spider()方法,在关闭爬虫是调用close_spider()方法。我们给他们添加启动数据库和关闭数据库的操作。
后面是最重要的方法,process_item()方法就是用来对item进行操作的。我们这里主要就是对数据库进行一个插入操作。
首先我们需要在items.py文件中加入一个 table_name = 'music'的属性,也就是相当于一个数据库表名。这样做方便我们将这个属性传到process_item()方法,我们需要调用数据库的update方法:
def process_item(self, item, spider):
self.db[item.table_name].update({'id': item.get('id')}, {'$set': dict(item)}, True)
return item
这个方法有三个参数,第一个参数传入数据库查询的字段,我们使用音乐的id来进行查询。
第二个参数就是我们的item数据,我们将他转化为字典形式。
第三个参数至关重要,我们传入True。意思是如果我们查询到相同的数据,我们就做更新操作,如果没有查询到相同的数据就做插入操作。这就相当于我们己做了插入数据库同时有做了去重的操作。
最后
好了,这样我们的爬虫就完成了,整理完代码运行起来吧。
项目地址
谢谢阅读