大家好,点开文章大家应该可以听到一曲大气恢弘的音乐,仿佛置身于江湖中,而自己是一名行侠仗义的侠客。见多了江湖的纷扰,你早已经累了,功名利禄对你来说不如一壶好酒。你骑马田间,而这时已是傍晚时分,起风了,你看这远方的夕阳,心生感慨。如果当初能够多一点勇气,那么这数十年来就不会是孤身一人了。你叹了口气,猛地抽了自己一巴掌,乱想什么呢,赶紧学习了。
通过上一篇文章,我相信大家对于Scrapy的使用也有了初步的了解。如果说要使用Scrapy写一些爬虫,也并非什么难事了。那么为了能写出更加复杂的爬虫,我们在本篇文章就来了解一下Scrapy的组件及他们的用法。
由于我在浏览Scrapy文档的时候,发现文档说的很是详细,如果我来写这篇文章的话,无疑是班门弄斧。
所以,本篇文章主要分享一下我在学习Scrapy中对于组件整体运作的理解。
理解
Scrapy 作为一个框架,整体的组件协作我们还是要做到流程清晰的。我们来看一下经典的 Scrapy 架构图:
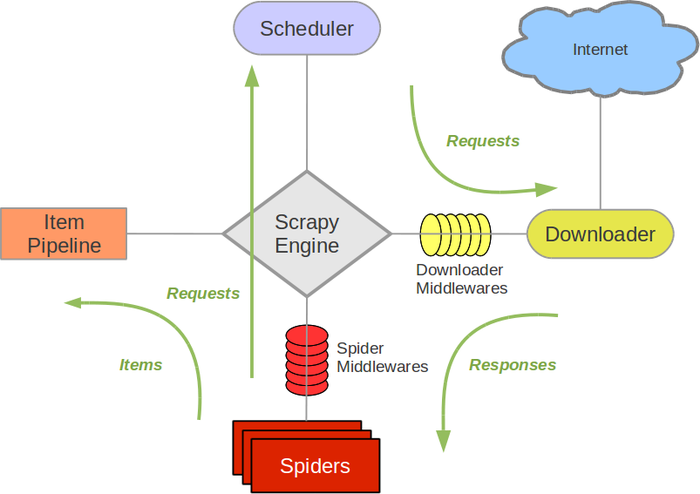
我们上一篇文章写的Scrapy项目大致流程就是:
- 确定爬虫名称和要抓取的初始网站;
- 请求网站获得响应数据
Response; - 解析
Response提取数据; - 有需要跟进的
url继续循环执行第二步; - 将需要的数据通过管道
Pipeline的处理; - 处理完的数据传给
Item保存。
图中的Scrapy Engine就是Scrapy的引擎,他处于中间位置,主要负责各个组件之间的通信,数据传递。
那上图的Spiders就是来完成爬虫的逻辑,还有网页数据的提取。他将要请求的url通过Scrapy Engine引擎,传给Scheduler(调度器)。
调度器接收了引擎发送来的Requests请求,按顺序排列整理。
由于所有的数据交流都是要通过引擎的,所以调度器是通过把处理好的Requests有发送给引擎,由引擎通过Downloader Middlewares(下载中间件)发送给Downloader(下载器)。
下载器通过下载中间件的设置来下载引擎传过来的Requests的url,并且将获取到的Response又发送给引擎(如果有下载失败的Requests,那么下载器会在后面接着下载)。
引擎收到Response后,再将它发送给Spiders,Spiders对Response解析提取出需要的数据(或者还有需要继续请求的url,会继续执行上面的循环)。
Spiders将这些数据发送给引擎,最后引擎将这些数据发送给Item Pipeline进行数据处理和存储。
那么这个流程就结束了。下面我给大家把相应组件还有Scrapy提供的命令行工具的文档地址整理给大家。
Spiders
我们上篇文章有用过Spider,就是我们爬虫类的基类。Spider他主要就是来完成爬虫的逻辑,还有网页数据的提取。他将要请求的url通过Scrapy Engine引擎,传给Scheduler(调度器),
对spider来说,爬取的循环类似下文:
以初始的URL初始化Request,并设置回调函数。 当该request下载完毕并返回时,将生成response,并作为参数传给该回调函数。
spider中初始的request是通过调用 start_requests() 来获取的。 start_requests() 读取 start_urls 中的URL, 并以 parse 为回调函数生成Request 。
在回调函数内分析返回的(网页)内容,返回 Item 对象或者 Request 或者一个包括二者的可迭代容器。 返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数(函数可相同)。
在回调函数内,您可以使用 选择器(Selectors) (您也可以使用BeautifulSoup, lxml 或者您想用的任何解析器) 来分析网页内容,并根据分析的数据生成item。
最后,由spider返回的item将被存到数据库(由某些 Item Pipeline 处理)或使用 Feed exports 存入到文件中。
文档地址:here
Item Pipeline
文档地址:here
Downloader Middleware
文档地址:here
Scrapy命令行工具
文档地址:here
选择器
文档地址:here
Scrapy源码
源码地址:here
最后
学一个框架最好的方法就是看他的文档和阅读他的源码,如大家认真看完上面的文档,那么对于Scrapy使用基本上是了然于胸了。那么下面的文章我们就来使用Scrapy写一些爬虫,知行合一才是最好的学习方法。
谢谢阅读