之前写爬虫的时候,经常遇到被封IP的情况。解决办法是控制爬虫请求的时间,这样效率低很多,而且一般网站都会有ip访问阈值监控,超过访问阈值仍然可能会被封。最直接的办法是更换ip,如果可以建议选择付费的代理服务,省事又便捷。当然网上也有很多免费代理,只不过这些代理能不能使用就需要我们自己去检测。
在几个月前,我参考github上的一些项目,搭建过一个代理池。主要作用就是抓取网上的免费代理,经过是否可用的检测,将可以代理放入数据库,并且定时对入库的代理进行检测,保证库中的代理一直是可用的。这样每次爬虫被封ip的时候,便向库中请求一个ip进行更换。最近正好需要使用大量的代理ip,就想起了这个项目,并且做了很大的改进。本篇文章主要写一下代理池的实现。
代理池设计
-
获取器:就是我们的爬虫接口,抓取免费ip,这里我们为了后面的可扩展性,需要支持自由添加爬虫进获取器;
-
数据库:我们选择
Mongodb存放有效的代理,上面文章写了关于Mongodb可扩展的封装,我们这里直接搬来使用; -
调度器:主要是用于检测爬虫是否有效,并添加有效代理入库,定制计划任务检测库中代理,控制爬虫的启动;
-
Api:为了更方便的调用新的代理,我们使用flask做外部接口。
由于免费代理可能在几十分钟后就不能使用,为了每次请求都尽可能从库中拿到可用代理,我们实现一个栈的数据结构,先进后出,后进先出。也就是说每次拿到代理都是从数据库的最右端获取,拿到最新检测过得有效代理。
代理池结构:
ProxyPool \
Api \
__init__.py
api.py
Spider \
__init__.py
get_proxy.py
Db \
__init__.py
db.py
Schedule \
__init__.py
adder.py
tester.py
schedule.py
config.py
run.py
获取器
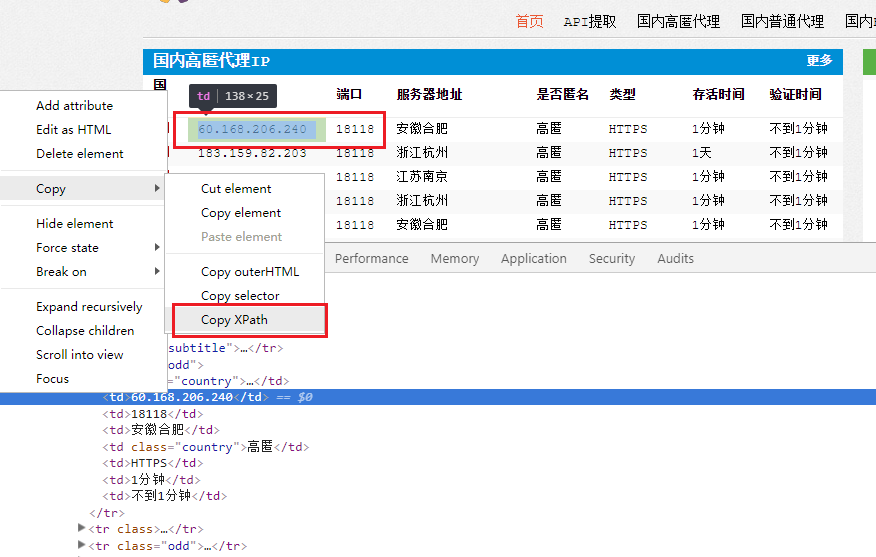
我们打开百度输入“免费ip”就可以看到很多提供免费ip的网站,这里我们选择幻代理,66代理,快代理,西刺代理。
主要是有很多代理站点的ip更新时间都很老了,大概率是不能使用的,就不浪费时间了。
抓取代理
对代理的抓取,不做多余的叙述,这里以西刺代理为例。对于这些网站的抓取其实很简单,过多的解释是浪费时间。
直接上代码:
# coding=utf-8
# __author__ = 'yk'
import requests
from lxml import etree
from requests.exceptions import ConnectionError
def parse_url(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'
}
try:
resp = requests.get(url, headers=headers)
if resp.status_code == 200:
return resp.text
return None
except ConnectionError:
print('Error.')
return None
def proxy_xici():
url = 'http://www.xicidaili.com/'
resp = parse_url(url)
html = etree.HTML(resp)
ips = html.xpath('//*[@id="ip_list"]/tr/td[2]/text()')
ports = html.xpath('//*[@id="ip_list"]/tr/td[3]/text()')
for ip, port in zip(ips, ports):
proxy = ip + ':' + port
yield proxy
我们使用xpath解析出代理。
可扩展
我们需要抓取的网站有四个,未来肯定会更多,为了能够更方便的扩展,我们需要写一个元类。元类主要是控制代理获取类的实现,在获取类中加入两个属性。用于存放类里的每个网站爬虫方法,以及所有爬虫的数量。方便我们在调度器中调用:
# Spider/get_proxy.py
class ProxyMetaclass(type):
"""
元类,在ProxyGetter类中加入
__CrawlFunc__和__CrawlFuncCount__两个属性
分别表示爬虫函数和爬虫函数的数量
"""
def __new__(cls, name, bases, attrs):
count = 0
attrs['__CrawlFunc__'] = []
for k in attrs.keys():
if k.startswith('proxy_'):
attrs['__CrawlFunc__'].append(k)
count += 1
attrs['__CrawlFuncCount__'] = count
return type.__new__(cls, name, bases, attrs)
class ProxyGetter(object, metaclass=ProxyMetaclass):
def proxy_ip66(self):
pass
def proxy_xici(self):
pass
def proxy_kuai(self):
pass
def proxy_ihuan(self):
pass
__init__方法和__new__方法的区别,我在一次面试中被问到过。这里做一个简单的解释:__new__是一个静态方法,用于控制类的实例创建,也就是在创建实例时调用他。而__init__是一个实例方法,用于初始化一个实例。
这里__new__方法给实例添加两个属性,他的参数分别表示当前类的对象本身(和self类似),name表示类的名字,bases是一个元组,表示类继承的父类集合,attrs表示类的方法集合,每一个方法是一个键值对。
str.startswith('ttt')是判断一个字符串是否以’ttt’开头,相对的有str.endswith('ttt')判断字符串是否以’ttt’结尾。这个方法很方便的将类方法中的爬虫方法过滤出来,将他放入__CrawlFunc__中。
为了方便调用我们还需要一个接口,供以调用爬虫方法:
class ProxyGetter(object, metaclass=ProxyMetaclass):
...
def get_raw_proxies(self, callback):
proxies = []
for proxy in eval("self.{}()".format(callback)):
print('Getting', proxy, 'from', callback)
proxies.append(proxy)
return proxies
python内置的eval函数作用不知道的可以自行查找,这里做一个简单解释:
>>> m = 5
>>> n = 3
>>> eval('m') + eval('n')
8
数据库
数据库我们直接使用上篇文章封装的类,不过未免存入相同ip,我们需要判断去重。
# Db/db.py
...
def put(self, proxy):
"""
放置代理到数据库
"""
num = self.proxy_num() + 1
if self.db[self.table].find_one({'proxy': proxy}):
self.delete(proxy)
self.db[self.table].insert({'proxy': proxy, 'num': num})
else:
self.db[self.table].insert({'proxy': proxy, 'num': num})
具体实现可以参考上篇文章。
调度器
调度器包含三个部分:
-
添加类:判断数据库中的代理数量是否达到最大阈值,进行启动爬虫和停止爬虫;
-
测试类:对爬取到的代理进行检测,将有效的代理放入数据库;
-
任务类:定时对数据库中的代理进行检测,用于启动整个调度器。
大致的逻辑就是这样,我们首先来实现一个测试类。
测试代理
之前我对代理的检测是直接加上代理,请求百度,如果请求成功返回200响应,就证明代理有效。后来我发现,就算是无效的代理,在请求百度的时候也会出现200响应。所以我选择http://2017.ip138.com/ic.asp这个测试ip的站点作为检测站。大部分人都是在一个服务器上跑代理池和别的爬虫项目,所以代理池应该有很快的速度,这里我们选择在添加代理时异步测试代理是否有效。
我们需要简单的理解python的异步库asyncio和基于asyncio实现的HTTP请求库aiohttp,这里我们使用aiohttp异步请求测试链接,检测代理是否有效,有效就将其放入数据库。
# Schedule/tester.py
import asyncio
import aiohttp
from Db.db import MongodbClient
# 将配置信息放入配置文件config.py
from config import TEST_URL
class ProxyTester(object):
test_url = TEST_URL
def __init__(self):
self._raw_proxies = None
def set_raw_proxies(self, proxies):
# 供外部添加需要测试的代理
self._raw_proxies = proxies
self._conn = MongodbClient()
async def test_single_proxy(self, proxy):
"""
测试一个代理,如果有效,将他放入usable-proxies
"""
try:
async with aiohttp.ClientSession() as session:
try:
if isinstance(proxy, bytes):
proxy = proxy.decode('utf-8')
real_proxy = 'http://' + proxy
print('Testing', proxy)
async with session.get(self.test_url, proxy=real_proxy, timeout=10) as response:
if response.status == 200:
# 请求成功,放入数据库
self._conn.put(proxy)
print('Valid proxy', proxy)
except Exception as e:
print(e)
except Exception as e:
print(e)
def test(self):
"""
异步测试所有代理
"""
print('Tester is working...')
try:
loop = asyncio.get_event_loop()
tasks = [self.test_single_proxy(proxy) for proxy in self._raw_proxies]
loop.run_until_complete(asyncio.wait(tasks))
except ValueError:
print('Async Error')
关于aiohttp的用法,大家可以参考这篇文章。也可以直接参考中文文档
aiohttp大致的get请求方式如:
async with aiohttp.ClientSession() as session:
async with session.get(url, headers=headers, proxy=proxy, timeout=1) as r:
content, text = await r.read(), await r.text(encoding=None, errors='ignore')
test()方法是启动测试的方法,使用asyncio库。asyncio的编程模型就是一个消息循环。最后我们获取一个EventLoop的引用:loop = asyncio.get_event_loop(),然后迭代出所有需要测试的代理,放入测试协程方法,将协程放入EventLoop中去执行。
这样,一个异步测试的类就实现了。
添加代理
这个类其实就是一个获取代理的循环,当库中代理数低于最低阈值,就启动爬虫获取代理,然后将这些代理放入测试类中去执行。为了方便添加类的调用,上面的测试类实现了放置需要测试代理的接口set_raw_proxies()方法,爬虫获取类也实现了供外部调用的方法get_raw_proxies(),这样我们只需要调用他们就可以了。
# Schedule/adder.py
from Db.db import MongodbClient
from Spider.get_proxy import ProxyGetter
from .tester import ProxyTester
class PoolAdder(object):
"""
启动爬虫,添加代理到数据库中
"""
def __init__(self, threshold):
self._threshold = threshold
self._conn = MongodbClient()
self._tester = ProxyTester()
self._crawler = ProxyGetter()
def is_over_threshold(self):
"""
判断数据库中代理数量是否达到设定阈值
"""
return True if self._conn.get_nums >= self._threshold else False
def add_to_pool(self):
"""
补充代理
"""
print('PoolAdder is working...')
proxy_count = 0
while not self.is_over_threshold():
# 迭代所有的爬虫,元类给ProxyGetter的两个方法
# __CrawlFuncCount__是爬虫数量,__CrawlFunc__是爬虫方法
for callback_label in range(self._crawler.__CrawlFuncCount__):
callback = self._crawler.__CrawlFunc__[callback_label]
# 调用ProxyGetter()方法进行抓取代理
raw_proxies = self._crawler.get_raw_proxies(callback)
# 调用方法测试爬取到的代理
self._tester.set_raw_proxies(raw_proxies)
self._tester.test()
proxy_count += len(raw_proxies)
if self.is_over_threshold():
print('Proxy is enough, waiting to be used...')
break
if proxy_count == 0:
print('The proxy source is exhausted.')
__CrawlFuncCount__和__CrawlFunc__两个属性这里可以很方便的使我们调用所有爬虫。
定时启动调度器
任务类是一个定时执行的程序,他实现一个定时启动调度器,检查数据库代理的方法。这里我们实现两个定时任务,一个是定时取部分代理调用测试类检测,一个是定时检测数据库中的代理是否低于最低阈值,调用添加类添加。所以,我们要实现两个定时任务的循环:
# Schedulr/schedule.py
import time
from multiprocessing import Process
from ProxyPool.db import MongodbClient
from .tester import ProxyTester
from .adder import PoolAdder
from config import VALID_CHECK_CYCLE, POOL_LEN_CHECK_CYCLE \
POOL_LOWER_THRESHOLD, POOL_UPPER_THRESHOLD
class Schedule(object):
@staticmethod
def valid_proxy(cycle=VALID_CHECK_CYCLE):
"""
从数据库中拿到一半代理进行检查
"""
conn = MongodbClient()
tester = ProxyTester()
while True:
print('Refreshing ip...')
# 调用数据库,从左边开始拿到一半代理
count = int(0.5 * conn.get_nums)
if count == 0:
print('Waiting for adding...')
time.sleep(cycle)
continue
raw_proxies = conn.get(count)
tester.set_raw_proxies(raw_proxies)
tester.test()
time.sleep(cycle)
@staticmethod
def check_pool(lower_threshold=POOL_LOWER_THRESHOLD,
upper_threshold=POOL_UPPER_THRESHOLD,
cycle=POOL_LEN_CHECK_CYCLE):
"""
如果代理数量少于最低阈值,添加代理
"""
conn = MongodbClient()
adder = PoolAdder(upper_threshold)
while True:
if conn.get_nums < lower_threshold:
adder.add_to_pool()
time.sleep(cycle)
def run(self):
print('Ip Processing running...')
valid_process = Process(target=Schedule.valid_proxy)
check_process = Process(target=Schedule.check_pool)
valid_process.start()
check_process.start()
代码中的几个变量需要放置配置文件:
# config.py
# Pool 的低阈值和高阈值
POOL_LOWER_THRESHOLD = 10
POOL_UPPER_THRESHOLD = 40
# 两个调度进程的周期
VALID_CHECK_CYCLE = 600
POOL_LEN_CHECK_CYCLE = 20
valid_proxy方法每次从数据库的左边开始拿到一般代理进行检测,这是因为主要是检测先添加进数据库的代理。然后调用测试类的set_raw_proxies()方法,过滤掉无效代理,将有效代理放于数据库右边。这样可以保证数据库中的代理都可以得到检测。
要拿到数据库的左侧一半代理,我们需要更改数据库get()方法。这一步参考上篇文章不做多余叙述,或者直接参考本项目源码,后面放上。
check_pool()方法接收最高和最低阈值和方法周期三个参数。定时判断数据库的代理数量是否低于最低阈值,选择性调用添加类添加代理。
最后开启两个进程,启动两个调度方法。
API
flask是做api最好的选择,我们只需要提供获取代理以及获取代理总数的接口。这一步主要就是对数据库的链接获取操作,flask路由只需提供/get和/counts路由。这只需要看一下flask文档的第一页就可以了,不做解释。
启动代理池
对于启动代理池,我们只需要启动flask的api,和调度器就可以了。
# run.py
from Api.api import app
from Schedule.schedule import Schedule
def main():
# 任务类的两个周期进程就是整个调度器
s = Schedule()
s.run()
app.run()
if __name__ == '__main__':
main()
项目地址
可以直接下载到本地,切换到项目目录。
安装依赖:pip install -r requirements.txt
启动:python run.py
示例
上面我们已经实现了我们的代理池,下面只是做一个基本的爬虫调用。
首先我们启动代理池:
>>> python run.py
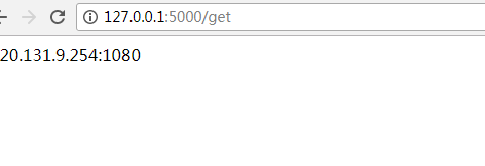
如果没有报错则,并且显示的信息正常,说明代理池已经启动了。这是打开浏览器访问http://127.0.0.1:5000/get就可以看到一条代理了。
最爬虫中调用:
import requests
def get_proxy():
resp = requests.get('http://127.0.0.1:5000/get')
proxy = resp.text
ip = 'http://' + proxy
return ip
def get_resp(url):
ip = get_proxy()
proxy = {'http': 'http://{}'.format(ip)}
resp = requests.get(url, proxies=proxy)
if resp.status_code == 200: print('success')
周末愉快!