最近一直有朋友问我改版的煎蛋网妹子图怎么爬,因为他们花费精力结果抓了一整个文件夹的防盗图。我之前在很久以前的一篇博客说过,对于这种js处理的网页,要想抓取到网页上看到的数据,大致有三种方法:
- Selenium结合浏览器驱动,直接获取加载js后的页面,解析数据。这种方法最为简单粗暴,不过速度会慢一点,处理煎蛋这样的网页有点大材小用;
- 直接使用python执行js文件,幸运的是PyV8库很符合要求,不过PyV8似乎不支持python3,python3可以使用PyExecJS库。这种方法也很简单,不过如果执行的js文件依赖pquery库的话,比较麻烦;
- 用python模拟js加密方式,拿到加密处理后的数据,这种方法就是本篇主要讨论的内容,优点是依赖少速度快,缺点是如果煎蛋加密方式改了,需要跟着改。
分析网页
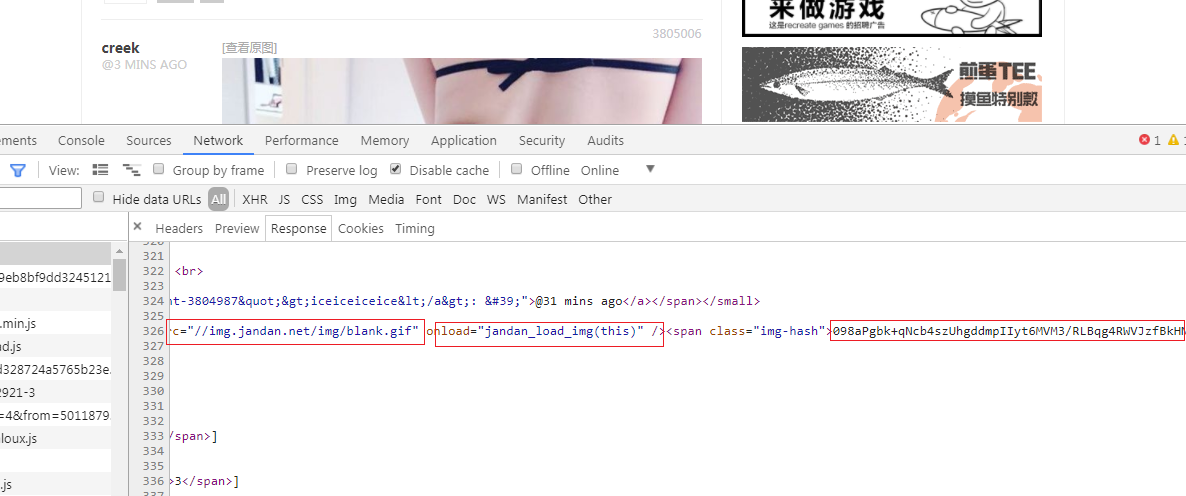
首先打开审查元素看他的实际响应内容,可以看到img标签中实际src属性的值是一个固定的值//img.jandan.net/img/blank.gif。而onload属性指向的是一个js的jandan_load_img()函数,this参数大多数情况是指的当前标签。后面接着span标签包含的一串hash值。
目前我们找到了jandan_load_img()函数,接着就是确定包含这个函数的js文件。方法很简单,在每一个返回的js响应中,去搜索。
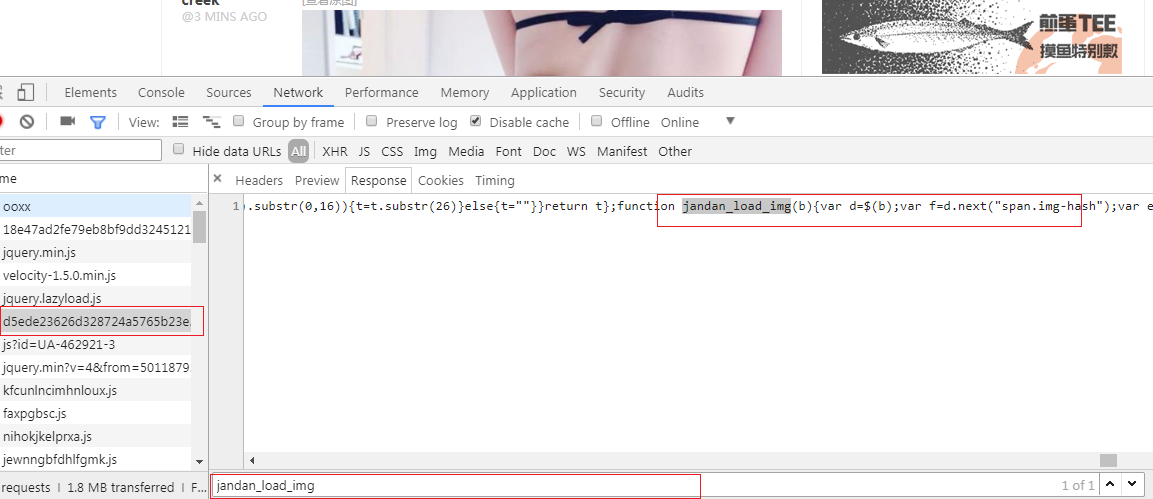
目前的js文件是经过压缩混淆过的,我们可以复制放到线上解压工具里解压。如果用的是Chrome,可以找到source文件,点击如下图标红框的按钮:
jandan_load_img()函数内容为:
function jandan_load_img(b) {
var d = $(b);
var f = d.next("span.img-hash");
var e = f.text();
f.remove();
var c = jdXFKzuIDxRVqKYQfswJ5elNfow1x0JrJH(e, "zE4N6eHuAQP8vkQPb0wcuEcWnLzHYVhy");
var a = $('<a href="' + c.replace(/(\/\/\w+\.sinaimg\.cn\/)(\w+)(\/.+\.(gif|jpg|jpeg))/, "$1large$3") + '" target="_blank" class="view_img_link">[查看原图]</a>');
d.before(a);
d.before("<br>");
d.removeAttr("onload");
d.attr("src", location.protocol + c.replace(/(\/\/\w+\.sinaimg\.cn\/)(\w+)(\/.+\.gif)/, "$1thumb180$3"));
...
}
可以看到js文件依赖PQuery库,它拿到img标签,接着拿到后面的span标签内容,然后将它和一个常量传给一串字符的这个函数,拿到这个一串字符的函数返回的内容,放到img和a标签中。
我们在当前js文件搜索是否有这个jdXFKzuIDxRVqKYQfswJ5elNfow1x0JrJH()函数,如果不出意外的话,可以搜索到2个函数。我们选择后面一个,内容如下:
var jdXFKzuIDxRVqKYQfswJ5elNfow1x0JrJH = function(m, r, d) {
var e = "DECODE";
var r = r ? r : "";
var d = d ? d : 0;
var q = 4;
r = md5(r);
var o = md5(r.substr(0, 16));
var n = md5(r.substr(16, 16));
if (q) {
if (e == "DECODE") {
var l = m.substr(0, q)
}
} else {
var l = ""
}
var c = o + md5(o + l);
var k;
if (e == "DECODE") {
m = m.substr(q);
k = base64_decode(m)
}
var h = new Array(256);
for (var g = 0; g < 256; g++) {
h[g] = g
}
var b = new Array();
for (var g = 0; g < 256; g++) {
b[g] = c.charCodeAt(g % c.length)
}
for (var f = g = 0; g < 256; g++) {
f = (f + h[g] + b[g]) % 256;
tmp = h[g];
h[g] = h[f];
h[f] = tmp
}
var t = "";
k = k.split("");
for (var p = f = g = 0; g < k.length; g++) {
p = (p + 1) % 256;
f = (f + h[p]) % 256;
tmp = h[p];
h[p] = h[f];
h[f] = tmp;
t += chr(ord(k[g]) ^ (h[(h[p] + h[f]) % 256]))
}
if (e == "DECODE") {
if ((t.substr(0, 10) == 0 || t.substr(0, 10) - time() > 0) && t.substr(10, 16) == md5(t.substr(26) + n).substr(0, 16)) {
t = t.substr(26)
} else {
t = ""
}
}
return t
};
拿到这段返回正确url的js代码,我们只要用python语言翻译过来就可以了。
抓取思路
- 请求网页拿到html;
- 从网页中解析出所有img标签后span标签包含的hash值;
- 正则匹配到html中对应js文件url,请求得到js代码;
- 正则匹配到js中
jandan_load_img()传递给解密函数的常量; - 将hash值和常量传递给解密函数,返回对应图片url;
- 下载图片。
翻译js函数
对面上面的步骤,我不做多余描述,主要说一下对js代码的翻译,后面会放整理后的代码地址。
如果要翻译上面的js代码,只需要搞清楚代码中调用的函数对应python什么函数就可以了,没有什么难点。
md5()是对md5.js的hex_md5()加密方式的封装:
function md5(a) {
return hex_md5(a)
}
这个方法就相当于python的hashlib库提供的md5摘要加密算法。感兴趣的朋友自行了解,由于后面多次调用此方法,我们对它进行一个封装:
def md5(str):
md5 = hashlib.md5()
md5.update(str.encode('utf-8'))
return md5.hexdigest()
js中的r.substr(0, 16)调用的是stringObject.substr(start,length)函数。substr()方法可在字符串中抽取从start下标开始的指定length数目的字符。这里注意的是length指的是长度,不是结束的下标,也就是它可以翻译为:
r[0:16]
r[16:32] # 注意不是r[16:16]
base64_decode(m)函数是对js的原生Base64编码api的封装:
function base64_decode(a) {
return window.atob(a)
}
大致使用如:
var str = 'javascript'
window.btoa(str) //转码结果 "amF2YXNjcmlwdA=="
window.atob("amF2YXNjcmlwdA==") //解码结果 "javascript"
Base64是一种用64个字符来表示任意二进制数据的方法。幸运的是python内置的有base64库,可以直接进行base64的编解码。我们也对他进行一个封装,方便阅读。这里有一个要注意的是,因为base64是把3个字节变为4个字节,base64编码的长度必须是4的倍数,所以对于不是4的倍数的字符,需要加上=把base64字符串的长度变为4的倍数。
def decode_base64(data):
return base64.b64decode(data + (4 - len(data) % 4) * '=')
var h = new Array(256);翻译过来就是h = list(range(256))
c.charCodeAt(g % c.length)调用的是js的stringObject.charCodeAt(index)函数,返回指定位置的字符的Unicode编码。这个返回值是0 - 65535之间的整数。这个方法相当于python的ord()函数。这行翻译过来就是:
b[g] = ord(c[g % len(c)])
k = k.split("");是将字符串k分解成单独的字符列表,在python中字符串本身也是一个可迭代对象,忽略就好。
chr()和ord()和python内置的chr()、ord()函数类似,我们直接调用对于函数,运行则回报错:ord() expected string of length 1, but int found。因为python中的ord()函数参数是一个str类型的参数,而k[g]实际上是一个字节,我们就不用调用ord()函数就可以了。即:
t += chr(k[g] ^ (h[(h[p] + h[f]) % 256]))
最后
如果进行到这里,基本上对于煎蛋网的抓取已经可以自己实现了。懒得去写的朋友可以直接看我整理好的代码:
拜了个拜。