目前 ChatGPT 无法直接与外部数据进行交互。如果我们能将自己的数据投喂给它,并且让它根据数据与我们对话,那么我们就能将 ChatGPT 变成自己的知识库。这种方法将使 ChatGPT 更加智能化和可定制化,更好地满足用户的需求。
因 OpenAI gpt-3.5-turbo模型有 4096 个 tokens 的限制,我们不能将一个大文本传递给 OpenAI。一个好的解决方法是使用 embeddings,但这会消耗我们的 tokens。而本文介绍的 pdfGPT,使用universal-sentence-encoder改进 embeddings。每次用户输入问题时,他会搜索文档中相关连的内容,然后将它传递给 ChatGPT,由 ChatGPT 回答用户的问题。
是什么
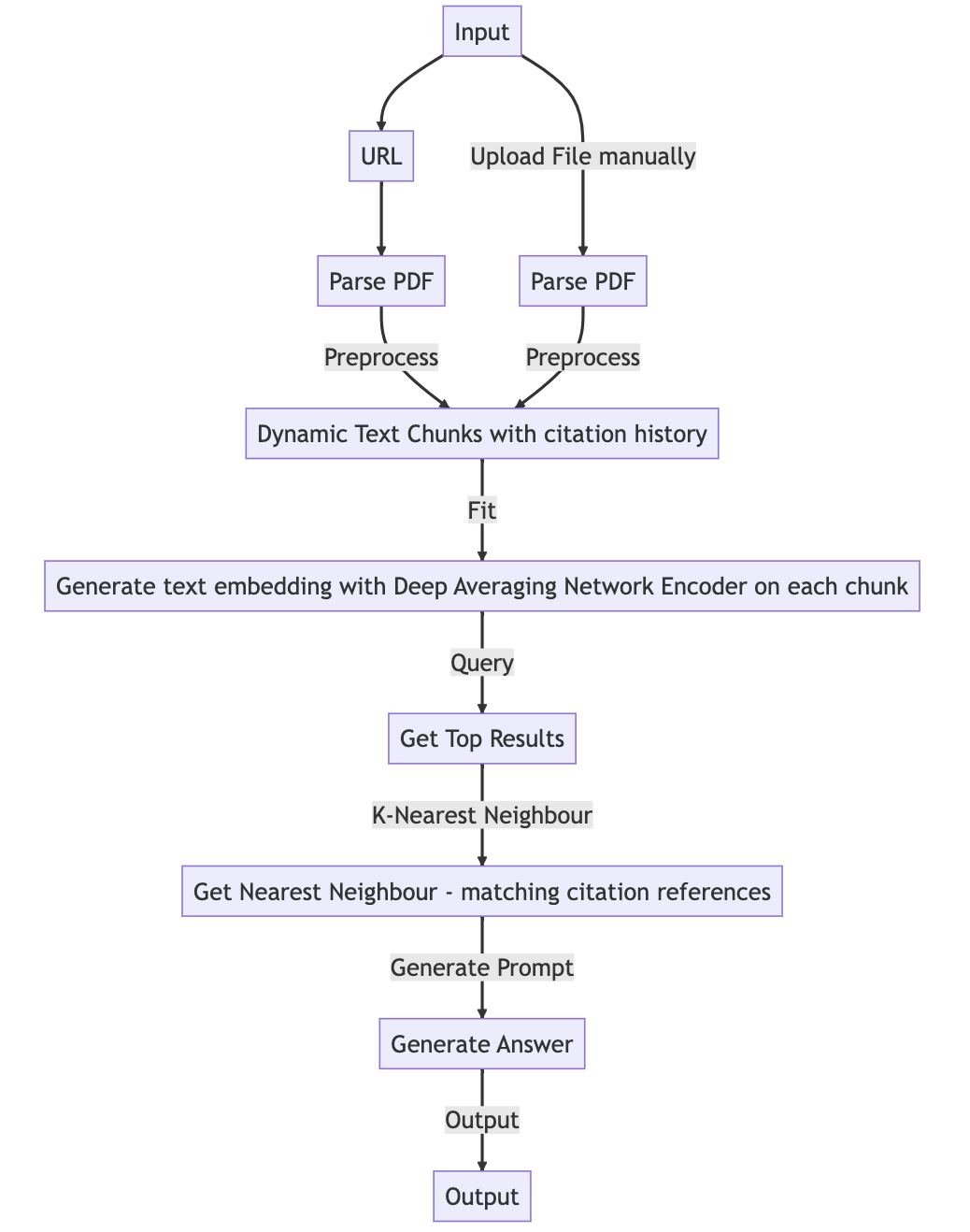
pdfGPT 允许用户使用 ChatGPT 与上传的 PDF 文件进行交流。该应用程序智能地将文档分成更小的块,并使用强大的Deep Averaging Network Encoder来生成 embeddings。
pdfGPT 对 pdf 文件内容进行语义搜索,并将最相关的 embeddings 传递给 ChatGPT。pdfGPT 自定义逻辑生成精确的回答。回答内容会将引用信息所在的文件页码放在方括号([])中,从而增加回答的可信度,并有助于快速定位相关信息。
开源地址:
https://github.com/bhaskatripathi/pdfGPT
项目 UML
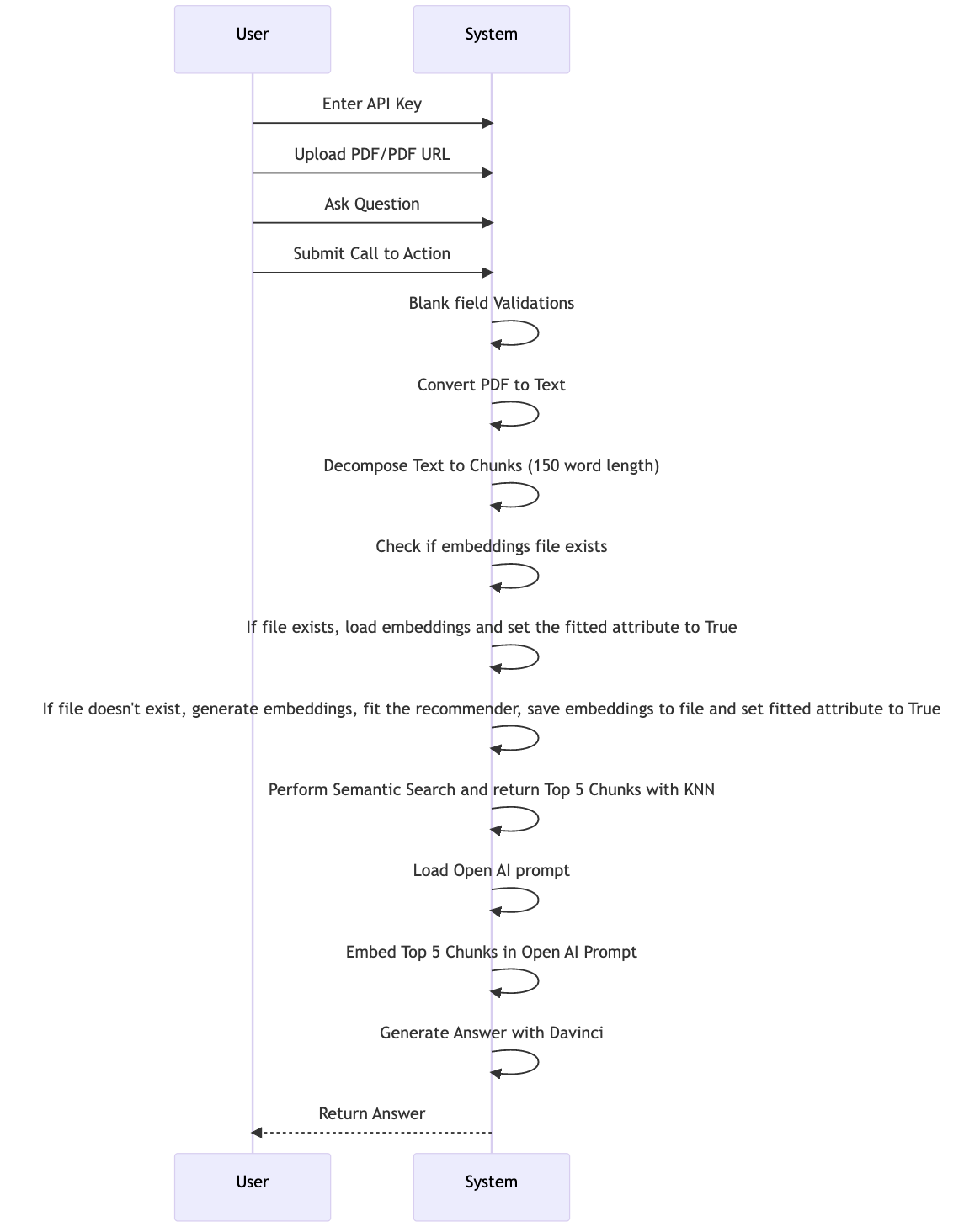
项目流程图
使用体验
这次我们依然白嫖Google colab的服务。现在让我们来体验下 pdfGPT 的能力吧。
安装依赖
!git clone https://github.com/bhaskatripathi/pdfGPT.git
!python -m pip install --upgrade pip
!pip install PyMuPDF
!pip install numpy
!pip install scikit-learn
!pip install tensorflow
!pip install tensorflow-hub
!pip install openai
!pip install gradio
这里直接根据依赖文件 pip install -r requirements.txt 时,会出现意料之外的报错。懒得去理会报错原因,我们直接手动安装这些依赖即可。
启动
%cd pdfGPT
!python app.py
项目通过 gradio 展示。我们直接根据表单提示,输入 OpenAI API key,并且上传我们的 PDF 文件或者输入文件的 URL 地址。然后我们在问题表单填入我们的问题,和 PDF 文件进行交流。
我以之前写的 C 站数据分析文章生成的 PDF 文件为例,我们向它提问:chilloutmix 是什么。它正确的返回了答案,并且标注了数据出处所在的页码。
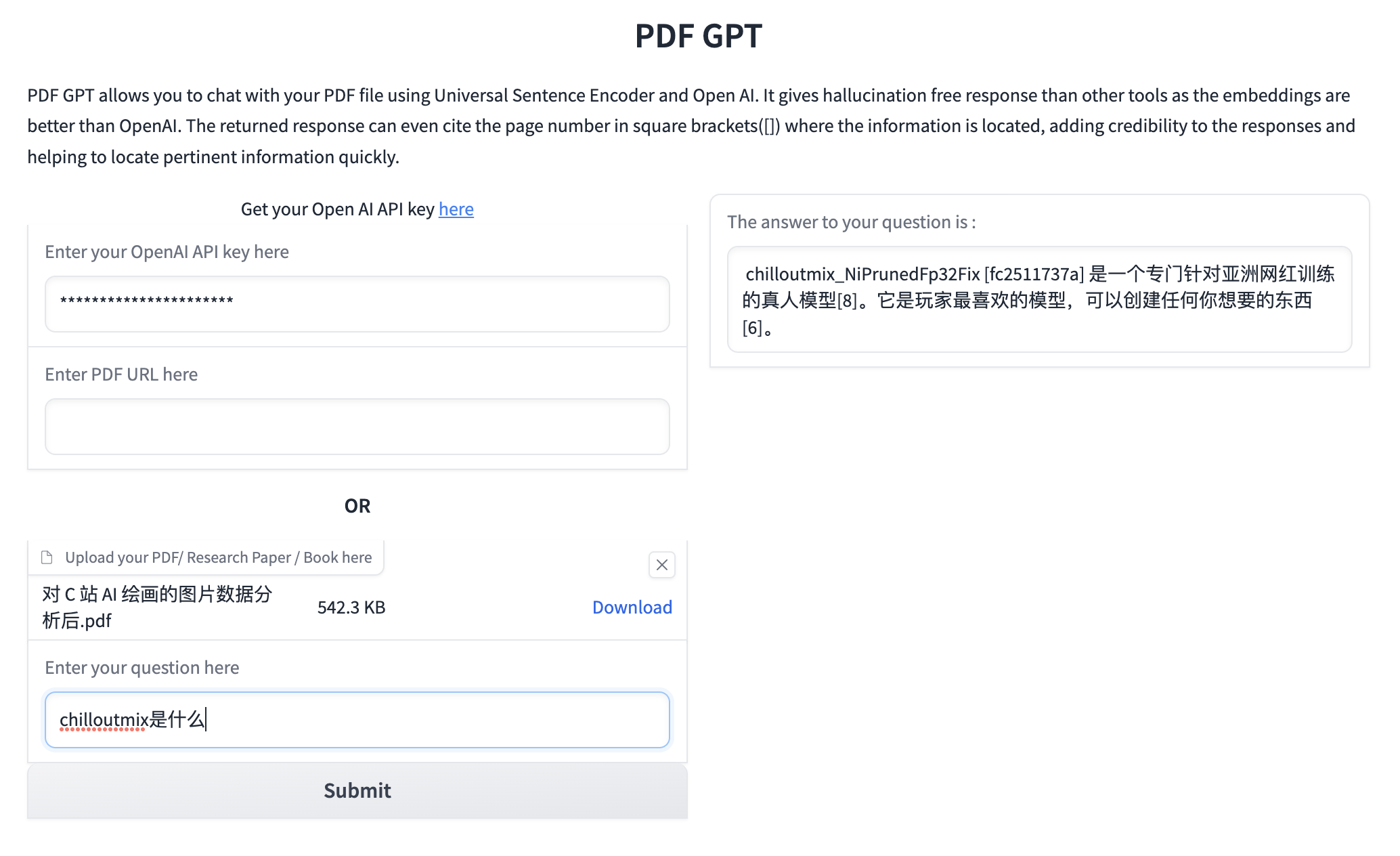
我们可以修改代码,添加 gradio 的 launch 参数share=True,向朋友分享自己的服务。添加 OpenAI key 输入框参数 type="password",使得前端输入 key 时,不明文展示在前端。
不足
当我们上传中文 PDF 大文件时,会出现openai.error.InvalidRequestError 报错。我们可以使用 OpenAI 官方提供的tiktoken 库计算 tokens 来拆分文本,以解决这个问题。这里大家自行处理。
总结
本文介绍了 pdfGPT ,并体验了它的能力。它向我们展示了通过投喂 PDF 文件内容给 ChatGPT,让他成为我们私人知识库的能力。
虽然它还有很大的不足,但它只是个 demo,大家可以自由探索。
我思考了下,这个方案比较适合的场景:就是那些不看文档就直接问问题的同事或者甲方,让他们自己问去吧。