我们在之前的文章中基本上掌握了Python爬虫的原理和方法,不知道大家有没有练习呢。今天我就来找一个简单的网页进行爬取,就当是给之前的兵书做一个实践。不然不就是纸上谈兵的赵括了吗。
好了,我们这次的目标是豆瓣图书Top250,地址是:https://book.douban.com/top250?start=0
准备
爬一个网页我们至少要知道自己需要什么信息,大家看截图:
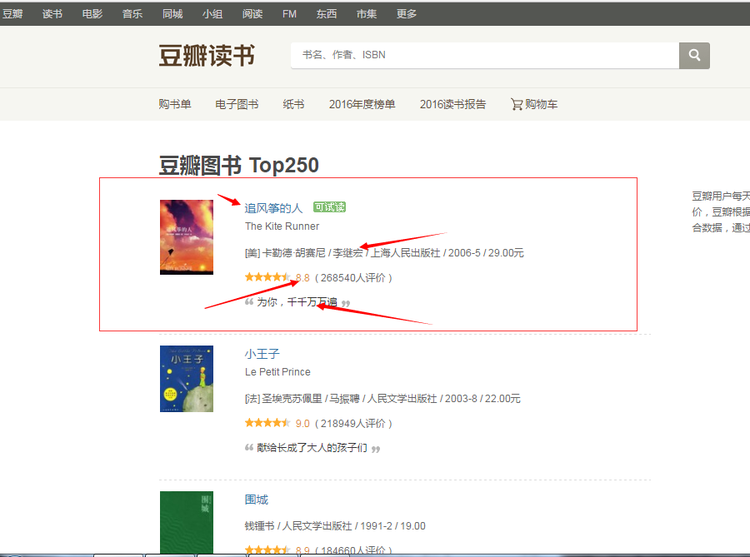
红色箭头标记的地方就是我们要获取的信息了,包括书的名字,作者和出版社信息,豆瓣评分和一句话简介。我们有了目标信息,就需要找到信息所在的页面源码,然后通过解析源码来获取到信息数据。那么,我们怎样获得页面 HTML 源代码呢?翻阅兵书,我们知道可以使用requests之计。代码实现如下:
import requests
resp = requests.get('https://book.douban.com/top250?start=0')
print(resp.text)
运行程序,我们就轻松的获得了敌军的 HTML 信息了。但是问题又来了,我们得到 HTML 信息后,怎样得到我们的目标数据呢?
深夜了,一轮弯月躲在云朵后面,窗外下着雨,我们坐在烛火前,翻阅兵书,顿时茅塞顿开,BeautifulSoup大法好。
我们打开浏览器,按f12到开发者工具,我们从网页源码里查找到数据位置,截图如下:
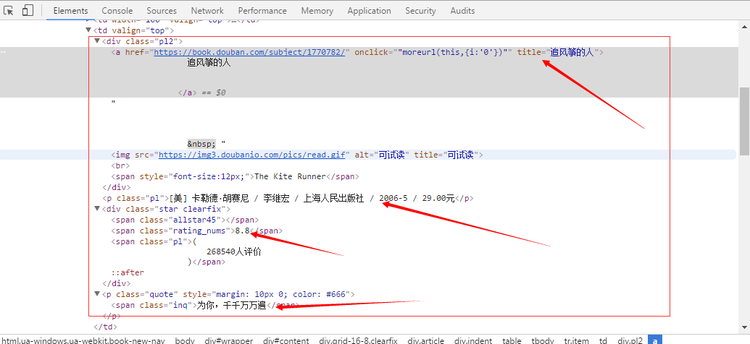
可以看到书名信息包含在class='pl2' div里面的a标签内,是a标签的title属性。发现目标位置后,就简单多了。我们利用BeautifulSoup来获得一个对象,按找标准的缩进显示的html代码:
from bs4 import BeautifulSoup
soup = BeautifulSoup(resp.text, 'lxml')
推荐大家使用lxml解析器,因为他快。如果安装lxml遇到问题的可以参考 上一篇文章 的方法。当然,如果大家怕麻烦,也完全可以使用Python的内置标准库html.parser.对我们获得结果并没有影响。
开始工作
现在我们要用到BeautifulSoup的find_all()选择器,因为我们这一页有很多书,而每一本书的信息都包含在class=pl2的div标签内,我们使用find_all()就可以直接得到本页所有书的书名了。我们用find()方法和find_all()方法来做一个比较:
# find_all()方法,
# 注意class是Python关键词,后面要加下划线_:
alldiv = soup.find_all('div', class_='pl2')
for a in alldiv:
names = a.find('a')['title']
print('find_all():', names)
# find()方法:
alldiv2 = soup.find('div', class_='pl2')
names2 = alldiv2.find('a')['title']
print('find():', names2 )
运行结果:
find_all(): 追风筝的人
find_all(): 小王子
# ...
# ...省略部分
# ...
find_all(): 三体Ⅲ
find(): 追风筝的人
Process finished with exit code 0
我们通过结果就可以看到两者之间的差距了,前者输出了一页的数据,而后者只输出了第一条数据。所以包括后面的信息,由于每一天数据所在标签是一样的,我们都是用find_all()方法。
上面的代码写的优雅点,就是这样实现,注意结果是一个 list:
# 书名, 注意是L小写,不是阿拉伯数字1
alldiv = soup.find_all('div', class_='pl2')
names = [a.find('a')['title'] for a in alldiv]
print(names)
这样书名数据我们就得到了,接下来是作者信息。方法和获取书名方法一样:
# 作者,由于信息在一个p标签内部,
# 我们获取到标签直接get_text()方法获得文本内容
allp = soup.find_all('p', class_='pl')
authors = [p.get_text() for p in allp]
运行结果:
['[美] 卡勒德·胡赛尼 / 李继宏 / 上海人民出版社 / 2006-5 / 29.00元',
'[法] 圣埃克苏佩里 / 马振聘 / 人民文学出版社 / 2003-8 / 22.00元',
'钱锺书 / 人民文学出版社 / 1991-2 / 19.00',
'余华 / 南海出版公司 / 1998-5 / 12.00元',
# ...
# ...省略部分结果
# ...
'高铭 / 武汉大学出版社 / 2010-2 / 29.80元',
'刘慈欣 / 重庆出版社 / 2010-11 / 38.00元']
后面的评分内容和简介内容也是一样获得,只是标签不同,但是方法一样,具体也不需要多余赘述。直接看实现代码:
# 评分
starspan = soup.find_all('span', class_='rating_nums')
scores = [s.get_text() for s in starspan]
# 简介
sumspan = soup.find_all('span', class_='inq')
sums = [i.get_text() for i in sumspan]
程序运行成功,我们就获得了4个list,分别是书名,作者,评分和简介内容。我们要把他们放在一起,打印出来,就是一页的数据信息了。
这里我们使用zip()函数,zip()函数在运算时,会以一个或多个序列做为参数,返回一个元组的列表。同时将这些序列中并排的元素配对。
for name, author, score, sum in zip(names, authors, scores, sums):
name = '书名:' + str(name) + '\n'
author = '作者:' + str(author) + '\n'
score = '评分:' + str(score) + '\n'
sum = '简介:' + str(sum) + '\n'
data = name + author + score + sum
我们使用换行符'\n‘给数据信息一点整齐的样式。我们可以查看到打印的结果,并没有所有数据黏在一起,显得丑陋。
获得信息后,就是保存数据了。保存数据也很简单,Python的文件读写操作就可以实现。代码如下:
# 文件名
filename = '豆瓣图书Top250.txt'
# 保存文件操作
with open(filename, 'w', encoding='utf-8') as f:
# 保存数据
f.writelines(data + '=======================' + '\n')
print('保存成功')
运行成功,我们就可以看到项目文件下面的 txt 文件了,上面保存了我们上面打印出来的内容。
书名:追风筝的人
作者:[美] 卡勒德·胡赛尼 / 李继宏 / 上海人民出版社 / 2006-5 / 29.00元
评分:8.8
简介:为你,千千万万遍
==================
# ...
# ...
书名:活着
作者:余华 / 南海出版公司 / 1998-5 / 12.00元
评分:9.1
简介:活着本身就是人生最大的意义
==================
但是,我们要的是 250 条数据,而不是一页的十几条数据,那么要怎么获得到所有的数据呢。我们可以检查页面的信息,可以看到页面一共 10 页,第一页的URL是https://book.douban.com/top250?start=0。而最后一页的 URL 是https://book.douban.com/top250?start=225
我们接着多看几页,第二页是https://book.douban.com/top250?start=25,第三页是https://book.douban.com/top250?start=50。
规律已经很清晰了,我们的页面的页数信息是最后的start=后面的数字。而且数字从0开始到225,每一页数字加 25.这就很简单了,我们以https://book.douban.com/top250?start=为基层URL,每一页在后面加页面的页数数字。就可以得到所有的页面 url 了。再以for循环迭代每一个 url,使用上面获取数据的方法,获得所有的数据信息。
获取所有页面URL的代码如下:
base_url = 'https://book.douban.com/top250?start='
urllist = []
# 从0到225,间隔25的数组
for page in range(0, 250, 25):
allurl = base_url + str(page)
urllist.append(allurl)
我们把他保存在 list 里面,好用循环迭代。
代码
那么,所有的功能都实现了。现在,我们只要将所有的代码组合起来,就可以实现我们需要的所有功能了。 上代码:
# -*- coding:utf-8 -*-
# author: yukun
import requests
from bs4 import BeautifulSoup
# 发出请求获得HTML源码的函数
def get_html(url):
# 伪装成浏览器访问
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
resp = requests.get(url, headers=headers).text
return resp
# 解析页面,获得数据信息
def html_parse():
# 调用函数,for循环迭代出所有页面
for url in all_page():
# BeautifulSoup的解析
soup = BeautifulSoup(get_html(url), 'lxml')
# 书名
alldiv = soup.find_all('div', class_='pl2')
names = [a.find('a')['title'] for a in alldiv]
# 作者
allp = soup.find_all('p', class_='pl')
authors = [p.get_text() for p in allp]
# 评分
starspan = soup.find_all('span', class_='rating_nums')
scores = [s.get_text() for s in starspan]
# 简介
sumspan = soup.find_all('span', class_='inq')
sums = [i.get_text() for i in sumspan]
for name, author, score, sum in zip(names, authors, scores, sums):
name = '书名:' + str(name) + '\n'
author = '作者:' + str(author) + '\n'
score = '评分:' + str(score) + '\n'
sum = '简介:' + str(sum) + '\n'
data = name + author + score + sum
# 保存数据
f.writelines(data + '=======================' + '\n')
# 获得所有页面的函数
def all_page():
base_url = 'https://book.douban.com/top250?start='
urllist = []
# 从0到225,间隔25的数组
for page in range(0, 250, 25):
allurl = base_url + str(page)
urllist.append(allurl)
return urllist
# 文件名
filename = '豆瓣图书Top250.txt'
# 保存文件操作
f = open(filename, 'w', encoding='utf-8')
# 调用函数
html_parse()
f.close()
print('保存成功。')
我们只用了36行的代码(去掉空行和注释)就实现了抓取豆瓣图书的数据了。大家是不是觉得很简单了,不要兴奋,这只是一个小白最基础的练手项目,大家快去找更有挑战性的项目实现吧。大家加油。
更新
多谢评论区**@joker57**朋友的提醒,之前写的时候确实没有发现这个问题,由于有的书籍没有简介,导致书籍抓取不全,而且有的书名和简介不对应。实在是误导大家,下面是对没有简介书籍的处理:
# 简介
sum_div = soup.select('tr.item > td:nth-of-type(2)')
sums = []
for div in sum_div:
sumspan = div.find('span', class_='inq')
summary = sumspan.get_text() if sumspan else '无'
sums.append(summary)
为了不影响其他的代码,我们用bs4的 CSS 选择器选择父级元素,然后在查找简介的span.inq子元素,如果为None则给他一个“无”。
经过检查,成功抓取250本书籍。
谢谢阅读