上一篇文章中我们抓取了豆瓣图书的数据,如果大家运行成功,并且看到文件夹下的 txt 文件了。是不是有一种刚接触编程,第一次输出Hello world!时的欣喜。和上一篇实践不同,我们这一次来爬取 煎蛋网 全站妹子图,并且保存到指定文件夹下。
爬取流程
- 从煎蛋网妹子图第一页开始抓取;
- 爬取分页标签获得最后一页数字;
- 根据最后一页页数,获得所有页
URL; - 迭代所有页,对页面所有妹子图片
url进行抓取;访问图片URL并且保存图片到文件夹。
开始
通过上一篇文章的爬取过程,我们基本上理解了抓取一个网站的大致流程。因为一个网站虽然有很多页,但是大部分网站每一页的HTML标签内容都是相同的。我们只要获取到一页的内容,就可以获得所有页的内容了。那么开始之前,我们来分析一下煎蛋网妹子图页面的URL。
第一页的 url:http://jandan.net/ooxx/page-1
第二页:http://jandan.net/ooxx/page-2
最后一页:http://jandan.net/ooxx/page-93
不难发现,煎蛋网的 url 的规律是比较简单的,每一页后面 page 的数字就是几。那么我们可以通过一个循环就可以获得所有的页面 URL 了。但是大家应该想到,这个网站每天都会更新,今天是 93 页,明天就会增加到94页了。如果每一都要爬一次的话,那么每次都要改一下代码页数信息了。这样实现起来虽然可以,但是不免有些愚蠢。
所以我们需要通过页面的标签信息让程序自己获得页数,我们访问http://jandan.net/ooxx/这个页面时,就相当于我们直接访问了最后一页。大家可以自己试试看。
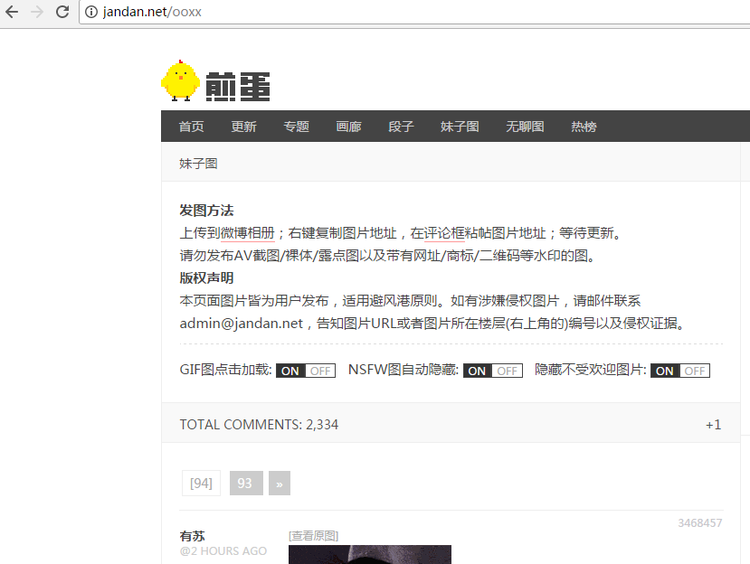
图中我们可以明确的看到最后一页的数字是94.只要通过这个页面的URL进行抓取就可以得到。我们先获得源码:
import requests
from bs4 import BeautifulSoup
url = 'http://jandan.net/ooxx/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, 'lxml')
我们按下f12,从页面源码中找到最后一页 94 所在的标签:
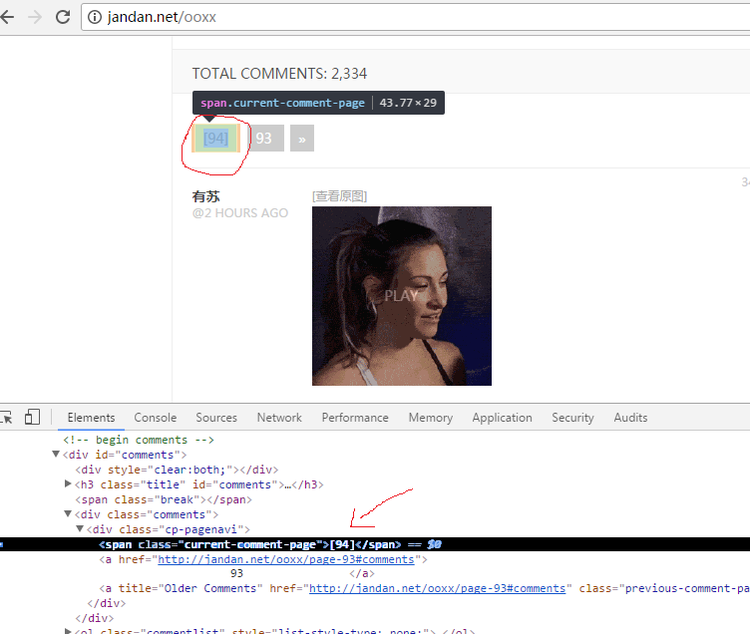
原来 94 就在这个span标签啊。接下来是不是很简单了:
# 获得最高页码数
allpage = soup.find('span', class_="current-comment-page").get_text()[1:-1]
由于标签内的 94 边包含一个[],大家不要以为只是一个list,只要[0]就可以获得的。我们完全可以使用type(),看一下他的属性,就知道它是一个字符串,我们利用切片去掉第一个和最后一个字符,就得到了页数了。
得到页数后,我们利用循环就可以得到所有页的url了:
urllist = []
# for循环迭代出所有页面,得到url
for page in range(1, int(allpage)+1):
allurl = base_url + 'page-' + str(page)
urllist.append(allurl)
我们把它保存到一个list中。
那么现在,我们得到所有页面的 url,就可以来获取每一页的内容了。我们以最后一页为例来进行抓取。
我们仍然使用审查元素,找到图片 url 所在的标签。仍然是老方法,获取到页面所有包含图片的img标签:
# css选择器
allimgs = soup.select('div.text > p > img')
只要一行代码,我们就成功获得所有标签了。这里使用了 CSS选择器,大家是否还记得这个方法呢。可以查看之前的文章或者BeautifulSoup的官方文档了解哦。如果大家对 CSS 不是很熟悉,或者根本不知道。也没关系,反正find_all()和find()方法也是可以实现的。不过这里我教大家一个简单的CSS选择器方法。
我们只要按f12打开浏览器的开发者工具,找到标签的位置,右击标签。就可以看到这个情况:
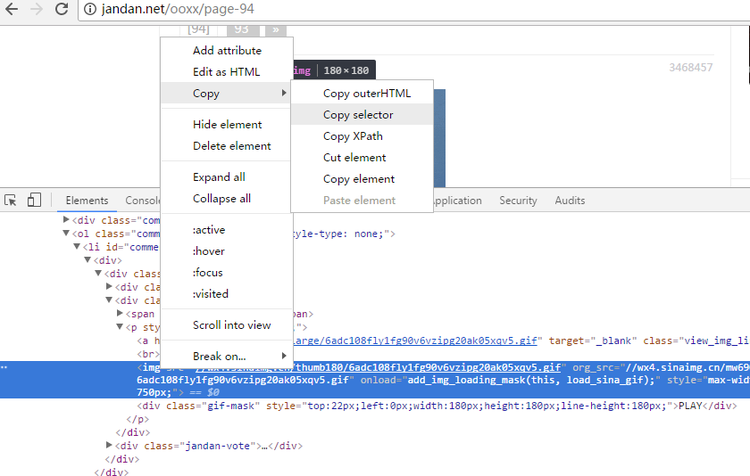
没错,我们直接Copy selector的内容,粘贴出来就是这样的字符串:#comment-3468457 > div > div > div.text > p > img
我们稍微去掉前面的一些标签,大多数情况下保留到父标签后面的内容就可以了。就是这样:div.text > p > img
我们放到代码中,运行一下就知道是不是成功了。
结果只一个列表:
[<img onload="add_img_loading_mask(this, load_sina_gif);" org_src="//wx4.sinaimg.cn/mw690/6adc108fly1fg90v6vzipg20ak05xqv5.gif" src="//wx4.sinaimg.cn/thumb180/6adc108fly1fg90v6vzipg20ak05xqv5.gif"/>, <img onload="add_img_loading_mask(this, load_sina_gif);" org_src="//wx4.sinaimg.cn/mw690/6adc108fly1fg90qymd8pg20dc0dcnph.gif" src="//wx4.sinaimg.cn/thumb180/6adc108fly1fg90qymd8pg20dc0dcnph.gif"/>, <img onload="add_img_loading_mask(this, load_sina_gif);" org_src="//wx4.sinaimg.cn/mw690/6adc108fly1fg90s98qsbg207e08mu10.gif" src="//wx4.sinaimg.cn/thumb180/6adc108fly1fg90s98qsbg207e08mu10.gif"/>, <img onload="add_img_loading_mask(this, load_sina_gif);" org_src="//wx3.sinaimg.cn/mw690/6adc108fly1fg90v51p5eg20a00dchdv.gif" src="//wx3.sinaimg.cn/thumb180/6adc108fly1fg90v51p5eg20a00dchdv.gif"/>, <img src="//wx4.sinaimg.cn/mw600/a1b56627gy1fdb7851js0j20ku4xcx6q.jpg"/>, <img src="//wx4.sinaimg.cn/mw600/a1b56627gy1fdb78fw14yj20dc46pb2a.jpg"/>, <img src="//wx3.sinaimg.cn/mw600/a1b56627gy1fdb78hqr1kj20dc1i0x02.jpg"/>, <img src="//wx4.sinaimg.cn/mw600/a1b56627gy1fdb78ldnwbj20ku3ei4qq.jpg"/>, <img src="//wx4.sinaimg.cn/mw600/a82b014bly1fg8gkj95toj21kw1kwh3s.jpg"/>, <img src="//wx4.sinaimg.cn/mw600/a82b014bly1fg8gkhmfraj21kw11xgth.jpg"/>, <img src="//wx2.sinaimg.cn/mw600/a82b014bly1fg8gklclivj21kw2dc1dg.jpg"/>, <img src="//wx2.sinaimg.cn/mw600/a82b014bly1fg8eohjekwj21421jkah5.jpg"/>]
很显然,这一页的图片URL都在这里。 接下来就是提取img标签的src属性了。
for img in list:
urls = img['src']
# 判断url是否完整
if urls[0:5] == 'http:':
img_url = urls
else:
img_url = 'http:' + urls
由于有的标签内url并不完整,所以这里我们进行一次判断。如果不完整就给他补全。
好了,图片的 url 都获得了,接下来就是保存图片了。大家还记得之前我们介绍Requests模块的时候,有过保存图片的演示。
因为万维网中每个图片,每个视频都有唯一的 url 指向它们。所以我们只要访问这个 url,并且获得图片的二进制数据,保存到本地就可以了。
imgs = requests.get(img_url,headers=headers)
filename = img_url.split('/')[-1]
# 保存图片
with open(filename, 'wb') as f:
# 直接过滤掉保存失败的图片,不终止程序
try:
f.write(imgs.content)
print('Sucessful image:',filename)
except:
print('Failed:',filename)
大家注意,获取图片二进制数据是.content方法,而不是.text。这里我们有一个错误过滤,因为保存的过程中会有一些文件保存错误的情况,我们直接过滤掉,不终止程序的运行。
好了,爬虫程序到这里基本上已经全部实现了。但是我们如果把所有的图片存放在一个文件夹中,而且还是代码所在文件夹,不免有些难看。我们可以自己指定他们存放的位置。这里需要用的Python内置的os库了,不清楚的伙伴可以自己查看资料哈。
# 创建文件夹的函数,保存到D盘
def mkdir(path):
# os.path.exists(name)判断是否存在路径
# os.path.join(path, name)连接目录与文件名
isExists = os.path.exists(os.path.join("D:\jiandan", path))
# 如果不存在
if not isExists:
print('makedir', path)
# 创建文件夹
os.makedirs(os.path.join("D:\jiandan", path))
# 切换到创建的文件夹
os.chdir(os.path.join("D:\jiandan", path))
return True
# 如果存在了就返回False
else:
print(path, 'already exists')
return False
我们只要传给这个函数一个路径参数就可以创建文件夹了。全部的功能都已经实现了,如果不出现以外的话,大家就可以在 d 盘看到这个文件夹了。
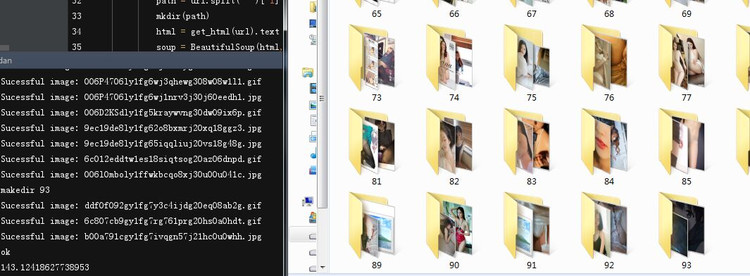
如果程序出现错误,可能是我们的程序访问过于频繁,网站封禁了我们的ip。这时,我们就要使用一个代理了。网上免费的代理很多,大家可以自己找,这里简单做一个使用代理的演示。由于是免费ip,不会存活太久就会不能使用,大家不要直接使用代码中的ip。后续可以带着大家一起代建一个自己的代理池。
proxies = {'http': '111.23.10.27:8080'}
try:
# Requests库的get请求
resp = requests.get(url, headers=headers)
except:
# 如果请求被阻,就使用代理
resp = requests.get(url, headers=headers, proxies=proxies)
代码
好了,最后上一下完整代码:
# -*- coding:utf-8 -*-
# author: yukun
import requests
import os
import time
from bs4 import BeautifulSoup
# 发出请求获得HTML源码
def get_html(url):
# 指定一个浏览器头
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
# 代理,免费的代理只能维持一会可能就没用了,自行更换
proxies = {'http': '111.23.10.27:8080'}
try:
# Requests库的get请求
resp = requests.get(url, headers=headers)
except:
# 如果请求被阻,就使用代理
resp = requests.get(url, headers=headers, proxies=proxies)
return resp
# 创建文件夹的函数,保存到D盘
def mkdir(path):
# os.path.exists(name)判断是否存在路径
# os.path.join(path, name)连接目录与文件名
isExists = os.path.exists(os.path.join("D:\jiandan", path))
# 如果不存在
if not isExists:
print('makedir', path)
# 创建文件夹
os.makedirs(os.path.join("D:\jiandan", path))
# 切换到创建的文件夹
os.chdir(os.path.join("D:\jiandan", path))
return True
# 如果存在了就返回False
else:
print(path, 'already exists')
return False
# 获得图片地址调用download函数进行下载
def get_imgs():
# 调用函数获得所有页面
for url in all_page():
path = url.split('-')[-1]
# 创建文件夹的函数
mkdir(path)
# 调用请求函数获得HTML源码
html = get_html(url).text
# 使用lxml解析器,也可以使用html.parser
soup = BeautifulSoup(html, 'lxml')
# css选择器
allimgs = soup.select('div.text > p > img')
# 调用download函数下载保存
download(allimgs)
# 执行完毕打出ok
print('ok')
# 获得所有页面
def all_page():
base_url = 'http://jandan.net/ooxx/'
# BeautifulSoup解析页面得到最高页码数
soup = BeautifulSoup(get_html(base_url).text, 'lxml')
# 获得最高页码数
allpage = soup.find('span', class_="current-comment-page").get_text()[1:-1]
urllist = []
# for循环迭代出所有页面,得到url
for page in range(1, int(allpage)+1):
allurl = base_url + 'page-' + str(page)
urllist.append(allurl)
return urllist
# 保存图片函数,传入的参数是一页所有图片url集合
def download(list):
for img in list:
urls = img['src']
# 判断url是否完整
if urls[0:5] == 'http:':
img_url = urls
else:
img_url = 'http:' + urls
filename = img_url.split('/')[-1]
# 保存图片
with open(filename, 'wb') as f:
# 直接过滤掉保存失败的图片,不终止程序
try:
f.write(get_html(img_url).content)
print('Sucessful image:',filename)
except:
print('Failed:',filename)
if __name__ == '__main__':
# 计时
t1 = time.time()
# 调用函数
get_imgs()
print(time.time() - t1)
经过计时,我们只需要146秒就爬取了全站的妹子图片了,大家注意身体。
谢谢阅读