大家好,这篇文章我们来看一下Cookie是什么,和他的一些用法。
什么是Cookie?
在计算机术语中是指一种能够让网站服务器把少量数据储存到客户端的硬盘或内存,或是从客户端的硬盘读取数据的一种技术。
先看看Cookie长什么样子,我们以知乎为例。打开Chrome的开发者工具(F12),点开Network,点击一个请求url,就可以看到请求头(Request Headers)里面的一个Cookie信息了。当然我们从上面的响应头中可以看到一个Set-Cookie的信息,这就是服务器向浏览器设置Cookie的一些信息,比如Cookie的作用域,时间等。
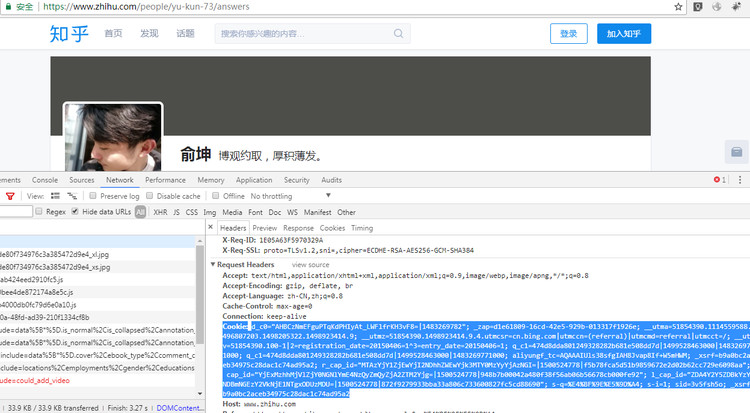
Cookie的用途
- 存储用户登录信息,判断用户是否登录;
- 保存用户浏览足迹;
Cookie是服务器在客户端存储的信息。这些信息是有服务器生成服务器解释的。
请求时,客户端需要把未超时的Cookies发送给服务器。服务器需要解析Cookies判断用户信息。
我们的浏览器会在你每次浏览网页是自动存储cookie,比如你打开清除浏览器浏览记录时,就会有cookie信息。
cookie给我们带来了很多便利,他还可以记录我们的浏览足迹,停留页面时间。比如你狂淘宝的时候,淘宝的推荐你喜欢的宝贝,就是根据你的cookie,获取你浏览过哪些商品,而生成的。
模拟登录演示
我们还是以知乎为例。https://www.zhihu.com/people/yu-kun-73/answers
这个URL是我的知乎信息页,当然大家可以使用自己的知乎页做例子。如果我们直接访问他,会看到上方的登录按钮,而是我已经登录了在访问呢。就不会显示登录按钮,而是个人编辑资料一些链接。
那么,如果我们使用爬虫去访问呢。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
}
url = 'https://www.zhihu.com/people/yu-kun-73/answers'
resp = requests.get(url, headers=headers).text
print(resp)
通过打印的结果,我们可以看到,html 代码里是有登录按钮的。这就证明我们并没有登录这个页面。那么,如果我们在爬取一些需要登录账号才可以爬取数据的网站时,我们必然是要解决登录问题的。那么如何实现登录呢。
答案就是我们的Cookie了。我们在之前的文章中说过,requests库在处理Cookie时,是非常简单的。我们只需要向添加‘User-Agent’一样添加请求cookies就可以了。
import requests
headers = {
'Cookie': # 你的登录过后的浏览器cookies,
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
}
url = 'https://www.zhihu.com/people/yu-kun-73/answers'
resp = requests.get(url, headers=headers).text
print(resp)
我们再次看打印信息,就可以看到有编辑个人资料的链接了。这就说明我们已经成功登录了。是不是很简单呢,别急,难的在后面呢。
最后
那么,如果我们要登录一些复杂的网站,比如新浪微博这种必须要登录才能获取信息的网站,使用cookie登录是肯定行不通的。因为这些网站会经常更新一些网站的算法,我们的cookie就会在工作一会失效,那么这些网站我们就需要向登录页post我们的登录信息。
这些登录信息参数一般都会存放在登录页的请求头下面的Form Data里面,我们只要携带这些信息Post,就可以顺利登录。但是如果遇到验证码,那么就很麻烦了。验证码的问题一直是考验爬虫的一个门槛,这个大家自己研究。
但是我们有一个最后的大杀器,Selenium+PhantomJS。这是什么呢?我们后面单独介绍。
谢谢阅读