Stable-Diffusion:一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。GitHub开源地址:https://github.com/Stability-AI/stablediffusion
stable-diffusion-webui:基于 Stable Diffusion 的基础应用,利用 gradio 搭建出的交互程序。
我们需要部署的就是stable-diffusion-webui。GitHub开源地址:https://github.com/AUTOMATIC1111/stable-diffusion-webui
环境要求
网络要求
安装资源大部分在国内访问速度不佳,建议自备极速方法,或者自行寻找国内镜像加速网站。
硬件要求
内存
不少于 16GB。 要容纳模型文件需要调高虚拟内存。
存储
40GB 以上可用硬盘空间。
显卡
显存不少于 4GB。 因为需要 CUDA 加速,所以只有英伟达显卡支持良好。(AMD 可用但速度明显慢于英伟达)
[!ERROR] 风险 过度玩耍(连续 3 天出图),显卡会有坏掉的风险
配置检查
检查显卡驱动
nvidia-smi
判断 CUDA 是否可用。不可用可手动安装。地址:CUDA
检查 PyTorch 是否成功载入 CUDA
import torch
print(torch.cuda.is_available())
输出True 为正常。
[!WARNING] 注意 torch 版本和 CUDA 版本需要对应。可在 torch 官网查看 torch 版本对应的 CUDA 版本。 如两者都安装了,但是输出为 False。需要对 CUDA 降级或升级。
查看 torch 对应的 CUDA 版本
import torch
torch.version.cuda
安装
Windows
- 安装Python 3.10.6 ,安装过程中需要勾选添加到PATH,手动把安装目录和pip所在目录添加到环境变量PATH中亦可。
- 安装git
- 挑个安装目录,右击点
git bash here,clone 项目到该目录:git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui - 双击项目目录下的
webui-user.bat
[!WARNING] 注意 安装过程中一些文件下载大约有7个G左右,需要保持硬盘空间充足。
报错安装依赖包异常
- 打开
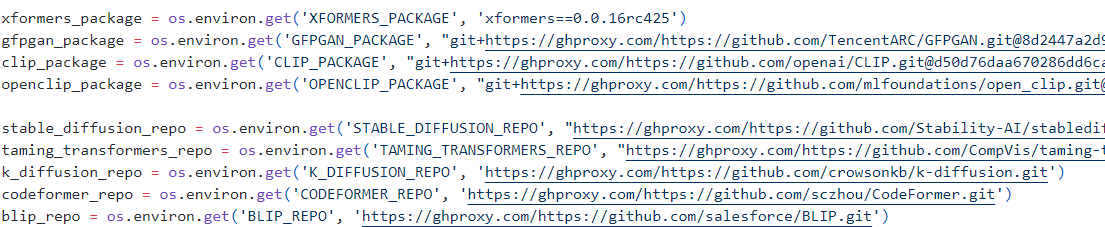
stable-diffusion-webui/launch.py文件。 - 找到
prepare_environment方法 - 在几个
https://github.com的链接前添加:https://ghproxy.com/。添加后的结果类似这样:https://ghproxy.com/https://github.com/… - 保存后继续执行
./webui.sh就可以了
Linux
- 安装依赖
# Debian-based:
sudo apt install wget git python3 python3-venv
# Red Hat-based:
sudo dnf install wget git python3
# Arch-based:
sudo pacman -S wget git python3
- 加载脚本
bash <(wget -qO- https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh)
参考官方安装 wiki
更新
git clone 的源项目,可直接使用git pull 更新代码。
网络问题
安装过程中出现:
- 形如
Connection timed out字样 - 形如
Connection was Reset字样 - 下载速度极慢
请设置代理,或者使用__
设置 pip 镜像
确保安装python时成功安装了pip并已经配置环境变了:
pip -V
设置镜像:
pip config set global.index-url https://mirrors.bfsu.edu.cn/pypi/web/simple
Git 拉取
如果拉去官方仓库速度太慢,可通过https://ghproxy.com/去拉取。
或者找国内镜像仓库。
CUDA out of memory
确保你拥有可以运行的最新 CUDA 工具包和 GPU 驱动程序.
在具有少量显存 (<=4GB) 的视频卡上运行时,可能会出现内存不足错误。可以通过命令行参数启用各种优化,牺牲一些速度来支持使用更少的 VRAM:
如果出现显存不足错误,请首先尝试 --medvram;
如果仍然出现显存不足错误,请改用 --medvram --always-batch-cond-uncond;
如果依旧出现显存不足错误,请尝试 --lowvram。注意这会让运行速度大幅降低。
如果还不行….
建议升级装备。
启动
启动前需确保models/Stable-diffusion文件夹下下载了任意的模型,供服务使用。模型下载地址可选择CIVITAI 和 Hugging Face。网络问题需自行解决。
Windows 用户编辑运行webui-user.bat 脚本。
Linux 用户第一次运行执行python launch.py,该脚步会自行安装环境,后面可直接执行python wenui.py。
第一次尝试
这里我用的模型是cetusix_whalefall。

在第一个输入框中输入我们的 Prompt:
(Hookah:1.2),holding smoking pipe, smoke,flask,girl,a long flexible rubber tube with a smoking pipe,waterpipe smoking,shisha,lethargy,staring into the distance,stained glass,zettai ryouiki, night,
这是我们期望得到的结果,()用于增加权重。
在第二个输入框中输入我们不希望看到的结果,Negative Prompt:
(worst quality:1.6),(low quality:1.6), easynegative,
调整参数
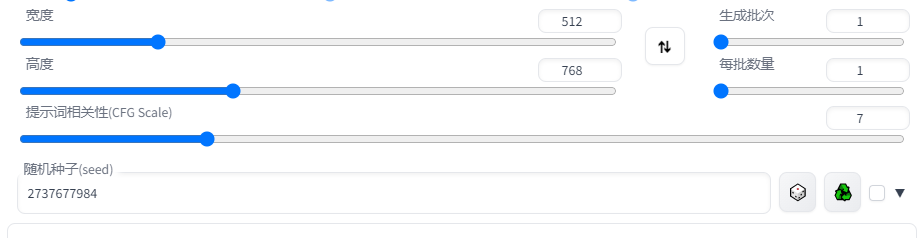
这里图片尺寸选择 512*768,显存足够大可以选更大的尺寸。
CFG Scale 表示提示词相关性权重,一般选择 7-9 这样。
seed 可以直接设置-1表示随机。
Steps 一般设置 20-30 这样,表示采样迭代步数。
Sampler 指定采样方法,这里选择DPM++ 2M Karras。
参数的具体解释,后面文章在说。
出图
当右边开始生成图片时,基本上就成功了。我们只需要等待图片生成结束即可。

最后
图片出来后,我们的本地化安装就完成了。但是还有些问题需要解决:
- SD-WebUI 中文本地化
- SD-WebUI 实例共享
- SD-WebUI 参数详解